Deep neural networks have been used widely to learn the latent structure of datasets, across modalities such as images, shapes, and audio signals. However, existing models are generally modality-dependent, requiring custom architectures and objectives to process different classes of signals. We leverage neural fields to capture the underlying structure in image, shape, audio and cross-modal audiovisual domains in a modality-independent manner. We cast our task as one of learning a manifold, where we aim to infer a low-dimensional, locally linear subspace in which our data resides. By enforcing coverage of the manifold, local linearity, and local isometry, our model --- dubbed GEM --- learns to capture the underlying structure of datasets across modalities. We can then travel along linear regions of our manifold to obtain perceptually consistent interpolations between samples, and can further use GEM to recover points on our manifold and glean not only diverse completions of input images, but cross-modal hallucinations of audio or image signals. Finally, we show that by walking across the underlying manifold of GEM, we may generate new samples in our signal domains.
Audiovisual Manifold Traversal
Setup
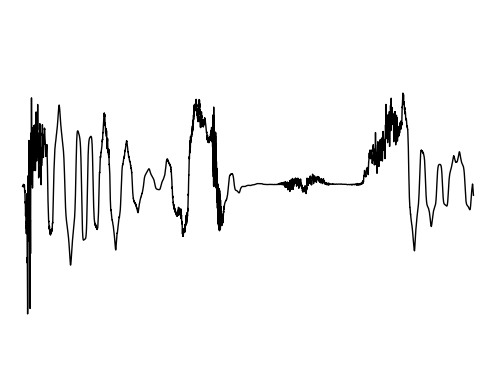
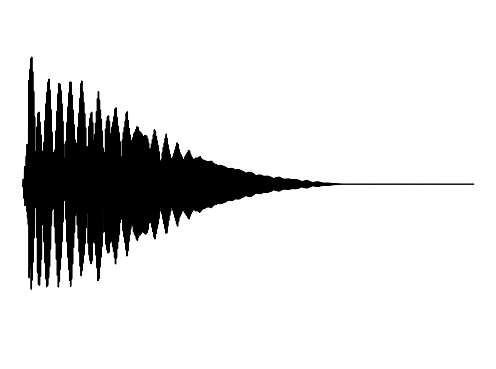
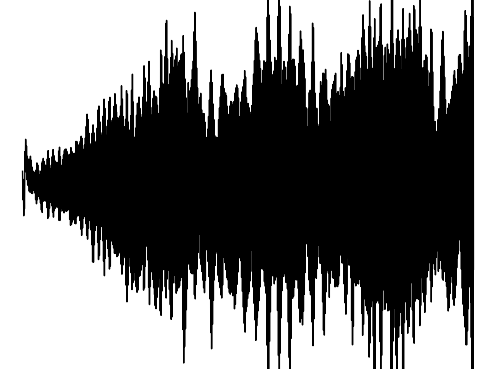
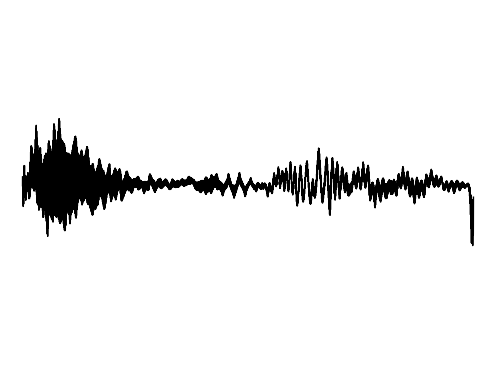
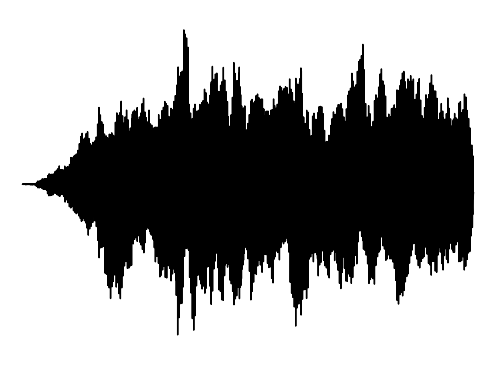
The following results verify that GEM can capture seperate data distributions in an modality independent manner. We utilize the same MLP and hyperenetwork architecture to represent manifold each seperate signal modality (utilizing two copies of the same MLP to encode a cross-modal signal). Function Distribution Networks (FDN)[Dupont et al. 2021] and StyleGAN2[Karras et al. 2019] denote additional methods for capturing the underlying signal modality, with architectural modifications to ensure proper signal generation. GEM is the only approach which can capture signals with high fidelity in an modality-independent manner.
Fitting Data Distributions
We show how GEM can fit audio and cross-modal audiovisual signals. Results of fitting images and 3D shapes may be found in the main paper.
Ground truth
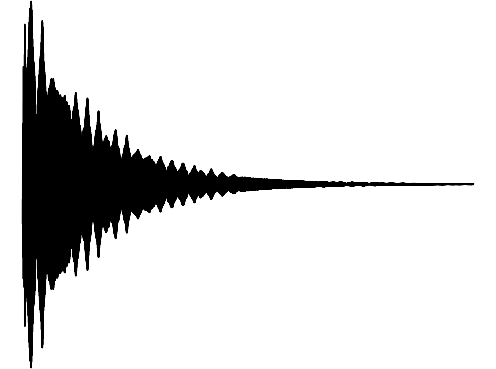
FDN
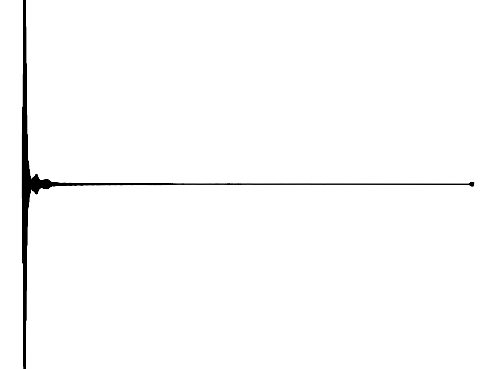
StyleGAN2
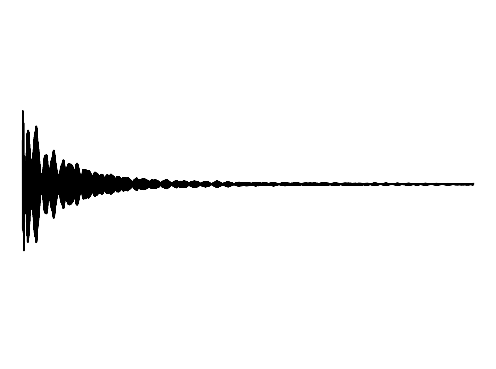
GEM
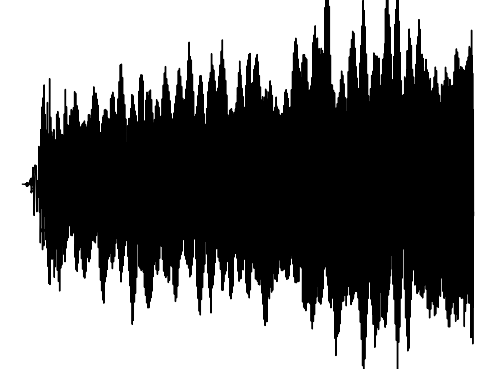
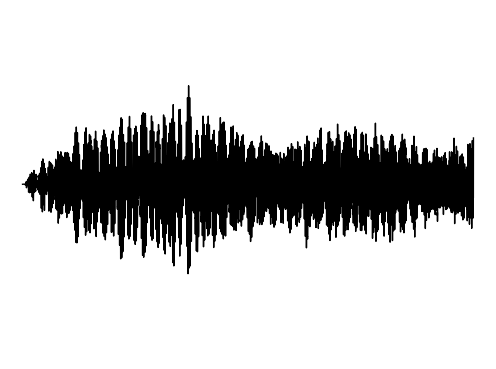
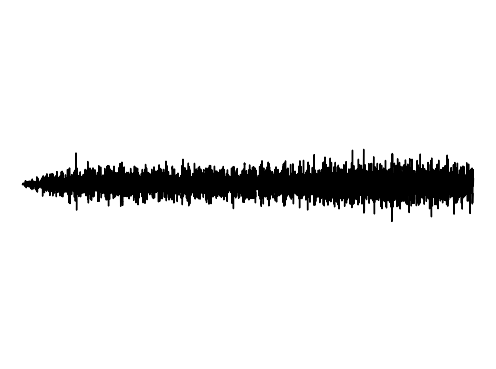
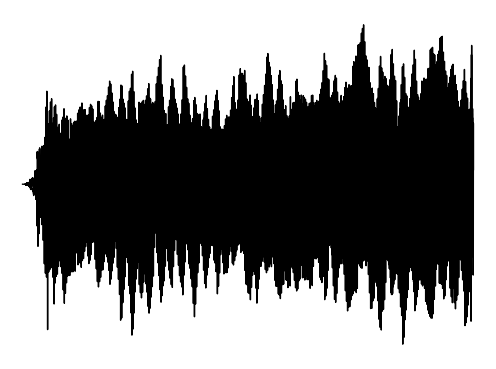








Interpolations
We next illustrate the underlying manifold that GEM captures across different signal modalities. Here, we visualize traversals on our manifold when interpolating between nearby training samples. We present traversals in the underlying image, shape, audiovisual modalities and then illustrate interpolations between separate audio signals.
Image Traversal
Shape Traversal
Audiovisual Traversal
Sample 1
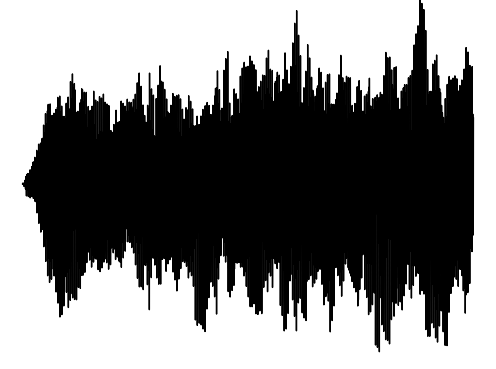
Interpolation 1
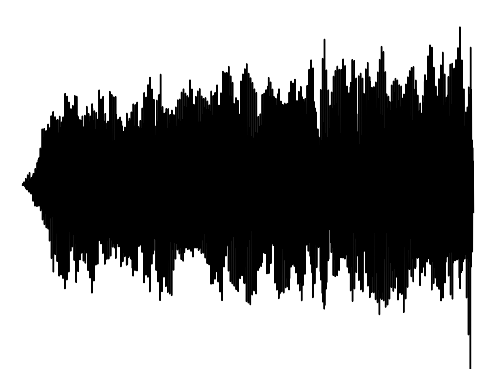
Interpolation 2
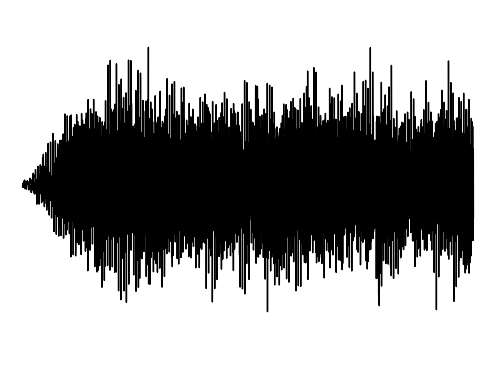
Sample 2
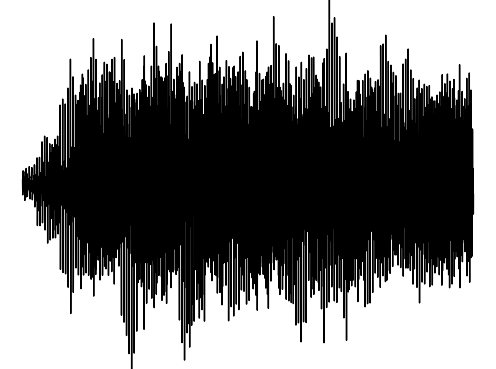
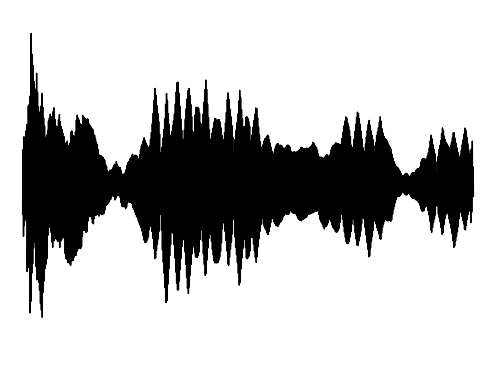
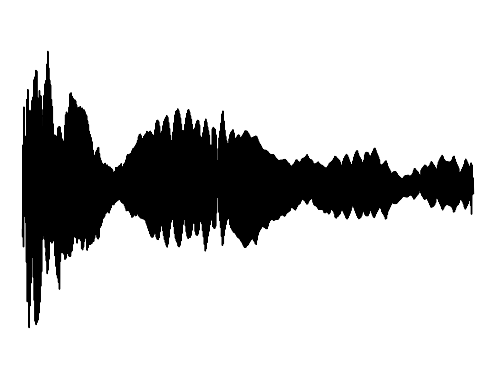
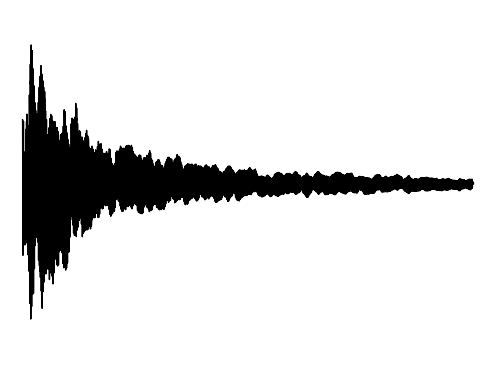
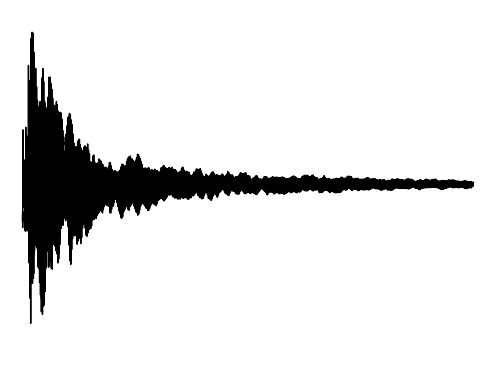
Cross-Modal Completion
We further assess the audiovisual manifold learned by GEM. We present examples of recovered samples when projecting partial signal consisting of only a input image into the underlying manifold in GEM. In the first set of images, GEM is able to generate seperate pitches of sounds dependent on the position of a bow on a cello. In the second set of images, GEM is able to either generate or not generate sounds, dependent if the person is blowing into the trombone.
Image Input

Hallucination 1
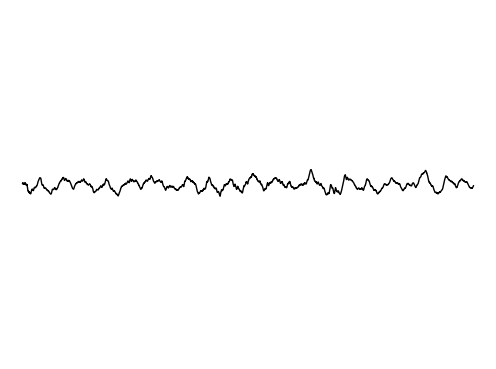
Hallucination 2

Hallucination 3

GT Audio
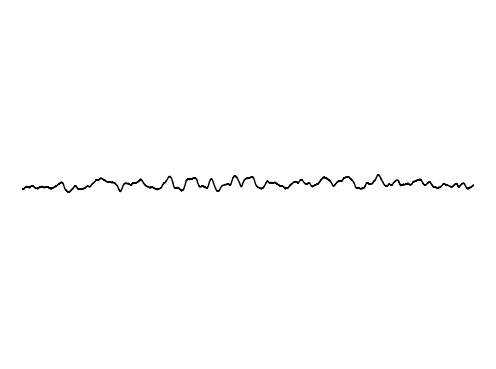

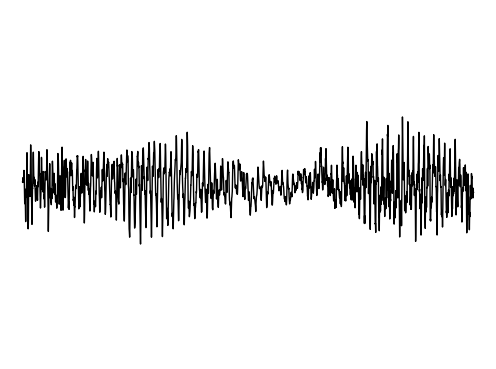
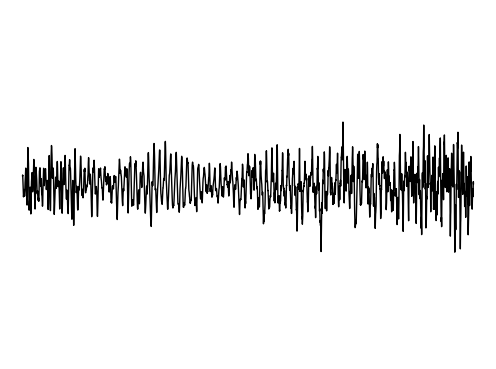
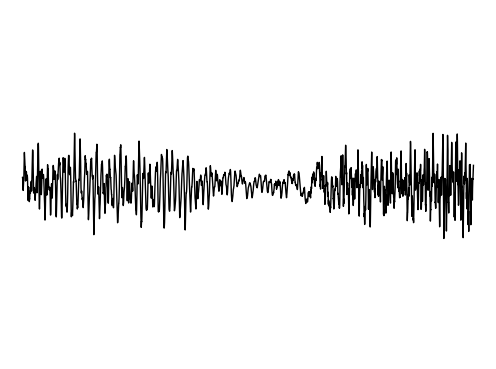
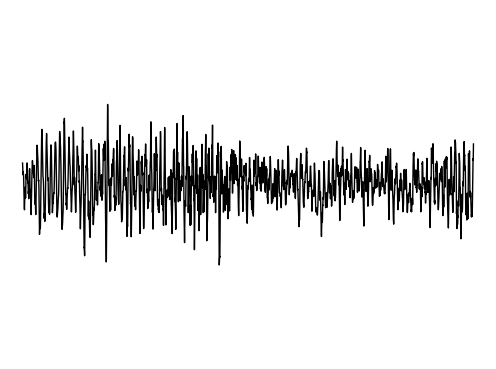

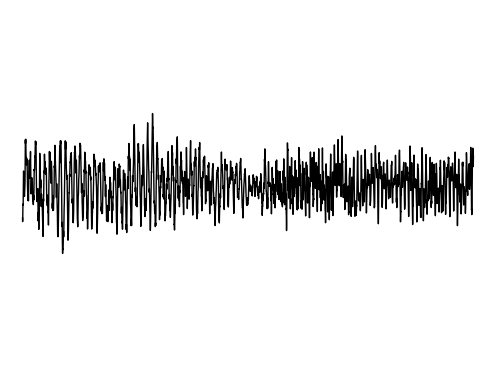
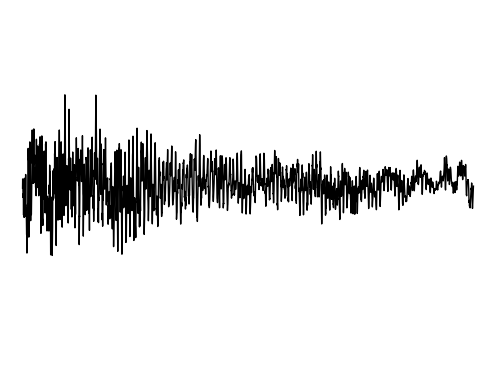
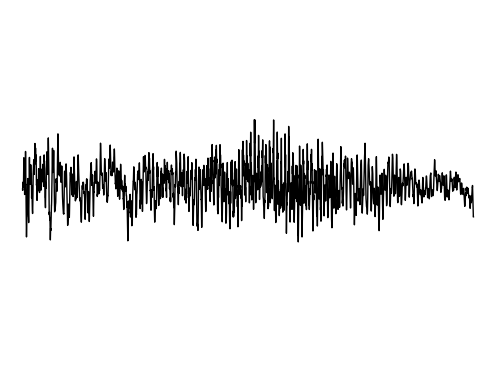
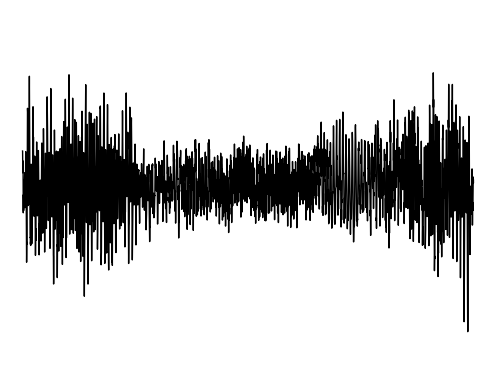
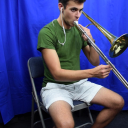
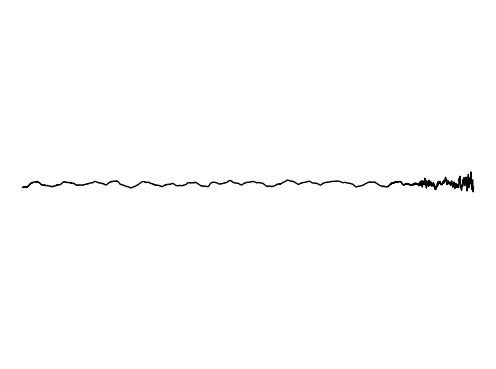
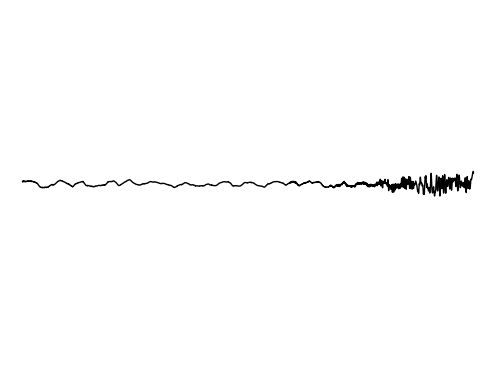
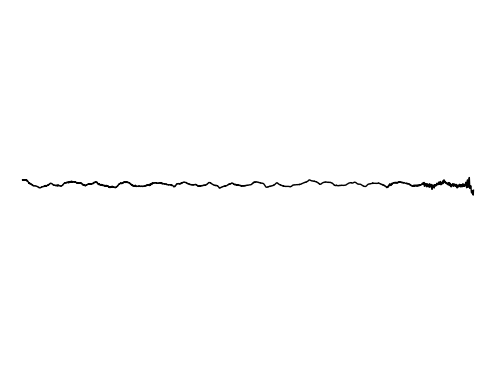
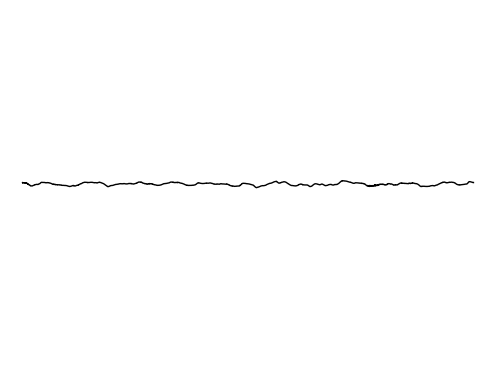

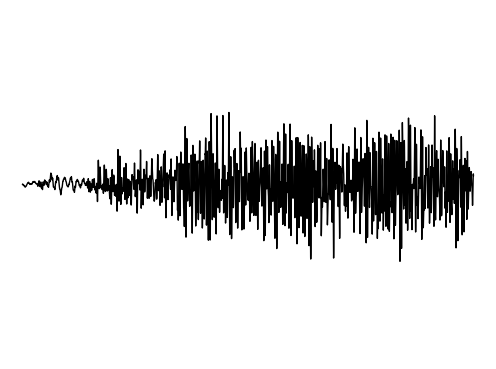
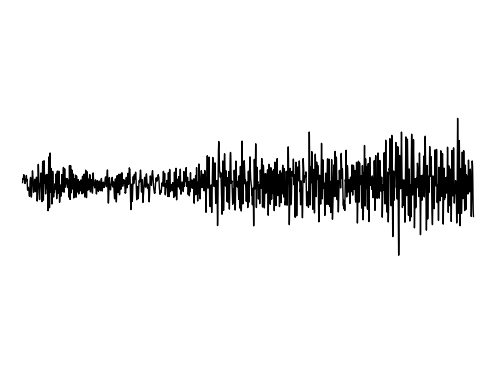
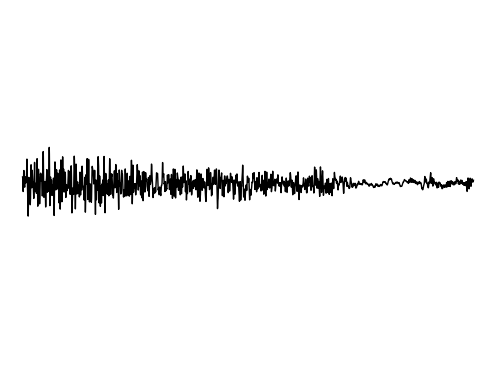
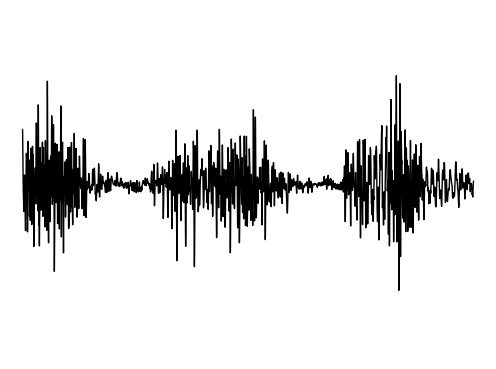
Image Inpainting
We further assess the ability of the manifold captured by GEM to restore images.
Input

Completion 1

Completion 2

Completion 3

Ground Truth











Generating Samples
Finally, we provide visualization on the ability to generate new samples from GEM by sampling in the underlying manifold. We present qualitative examples of generated audio clips and audiovisual samples utilizing GEM. Samples of images and 3D shapes may be found in the main paper.
FDN
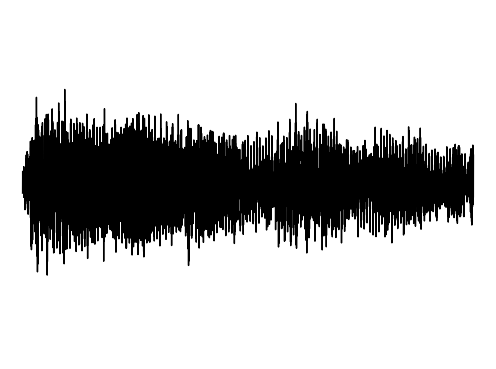
StyleGAN2
GEM









Paper
