We present Neural Descriptor Fields (NDFs), an object representation that encodes both points and relative poses between an object and a target (such as a robot gripper or a rack used for hanging) via category-level descriptors.
We employ this representation for object manipulation, where given a task demonstration, we want to repeat the same task on a new object instance from the same category.
We propose to achieve this objective by searching (via optimization) for the pose whose descriptor matches that observed in the demonstration.
NDFs are conveniently trained in a self-supervised fashion via a 3D auto-encoding task that does not rely on expert-labeled keypoints.
Further, NDFs are SE(3)-equivariant, guaranteeing performance that generalizes across all possible 3D object translations and rotations.
We demonstrate learning of manipulation tasks from few (~5-10) demonstrations both in simulation and on a real robot.
Our performance generalizes across both object instances and 6-DoF object poses, and significantly outperforms a recent baseline that relies on 2D descriptors.
Results
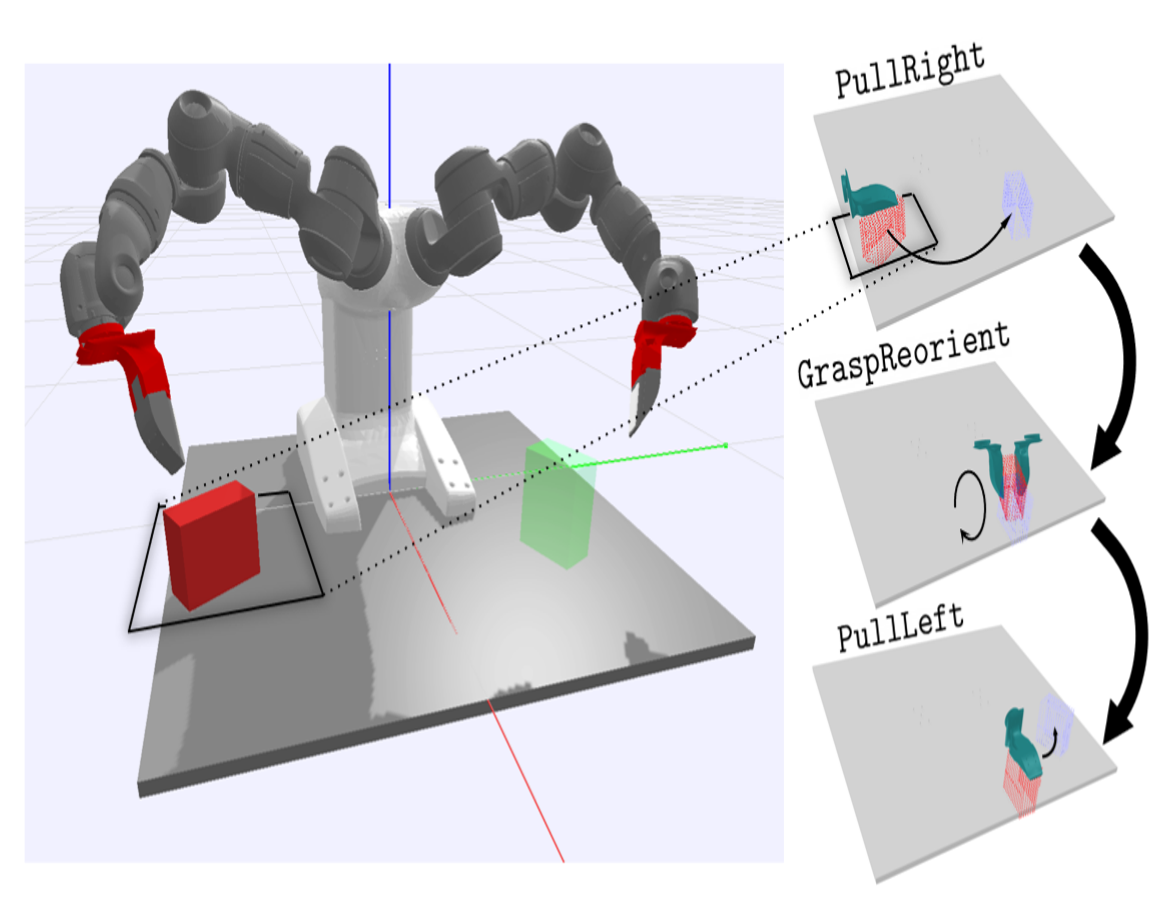
As humans, we are able to naturally and easily manipulate a wide variety of different objects from a single demonstration, regardless of the underlying pose or instance of the object. Inspired by this capability, in this paper,
we present a framework which can provably generalize a single manipulation demonstration of an object to an arbitrary novel pose of the object. Given a manipulation skill executed a upright mug, we may automatically
apply this demonstration to the mug when it is oriented either sideways or even upside-down. We further show that our framework enables us to transfer demonstrations on different mugs to novel instances of a mug.
Paper
Bibtex
@article{simeonovdu2021ndf,
title={Neural Descriptor Fields: SE(3)-Equivariant Object
Representations for Manipulation},
author={Simeonov, Anthony and Du, Yilun and Tagliasacchi,
Andrea and Tenenbaum, Joshua B. and Rodriguez, Alberto and Agrawal,
Pulkit and Sitzmann, Vincent},
booktitle = {ICRA},
year={2022}
}
Our Related Projects
Check out our related projects on neural fields and object representations for manipulation!
We present a framework for solving long-horizon planning problems involving manipulation of rigid objects that operates directly from a point-cloud observation. Our method plans in the space of object subgoals and frees the planner from reasoning about robot-object interaction dynamics by relying on a set of generalizable manipulation primitives. We show that for rigid bodies, this abstraction can be realized using low-level manipulation skills that maintain sticking contact with the object and represent subgoals as 3D transformations.
We present a method to capture the underlying structure of arbitrary data signals by representing each point of data as a neural field. This enables us to interpolate and generate new samples in image, shape, audio, and audiovisual domains all using the same identical architecture.
We present a method to capture a dynamic scene utilizing a spatial-temporal radiance field. We enforce consistency in this field utilizing a continuous flow field. We show that such an approach enables us to synthesize novel views in dynamic scenes captured using as little as a single monocular video, and further show that our radiance field can be utilized to denoise and super-resolve input images.
We demonstrate that the features learned by neural implicit scene representations are useful for downstream tasks, such as semantic segmentation, and propose a model that can learn to perform continuous 3D semantic segmentation on a class of objects (such as chairs) given only a single, 2D (!) semantic label map!
External Related Projects
Check out these relevant external projects on utilizing object representations for manipulation!
A method for self-supervised dense correspondence learning. Dense descriptors encoding correspondence are used as an object representation for manipulation. The authors demonstrate grasping of specific points on an object across potentially deformed object configurations, and using class-general descriptors to transfer specific grasps across different objects in a class.
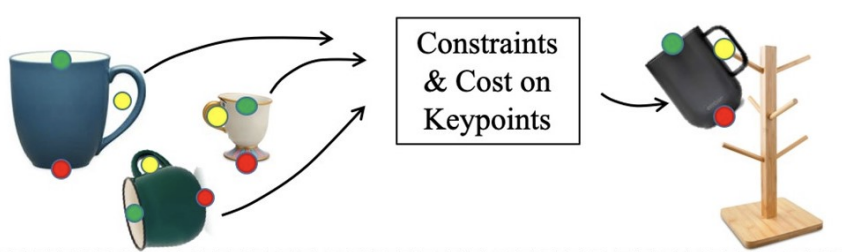
A formulation of category-level manipulation that uses semantic 3D keypoints as the object representation. This keypoint representation enables a simple and interpretable specification of the manipulation target as geometric costs and constraints on the keypoints, and is robust to large intra-category shape variation.