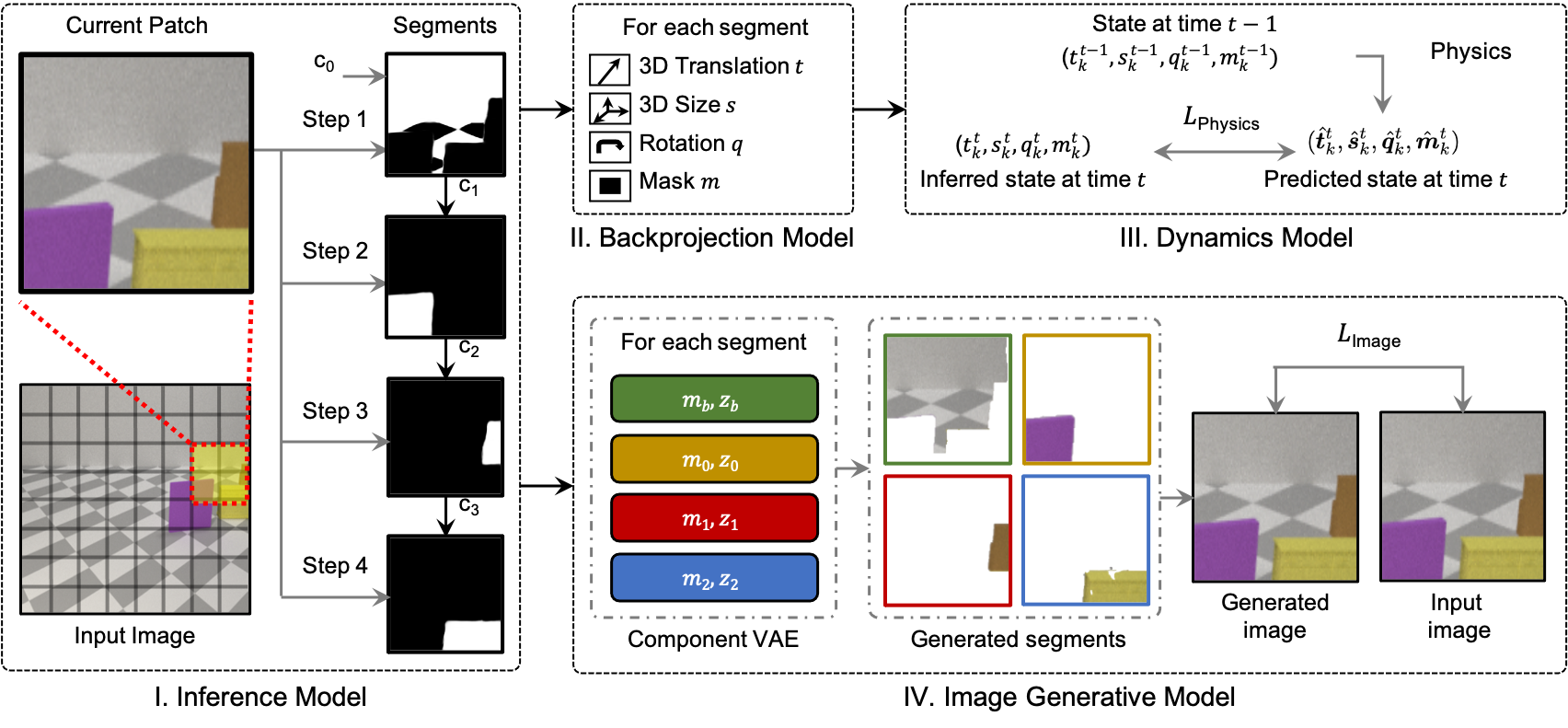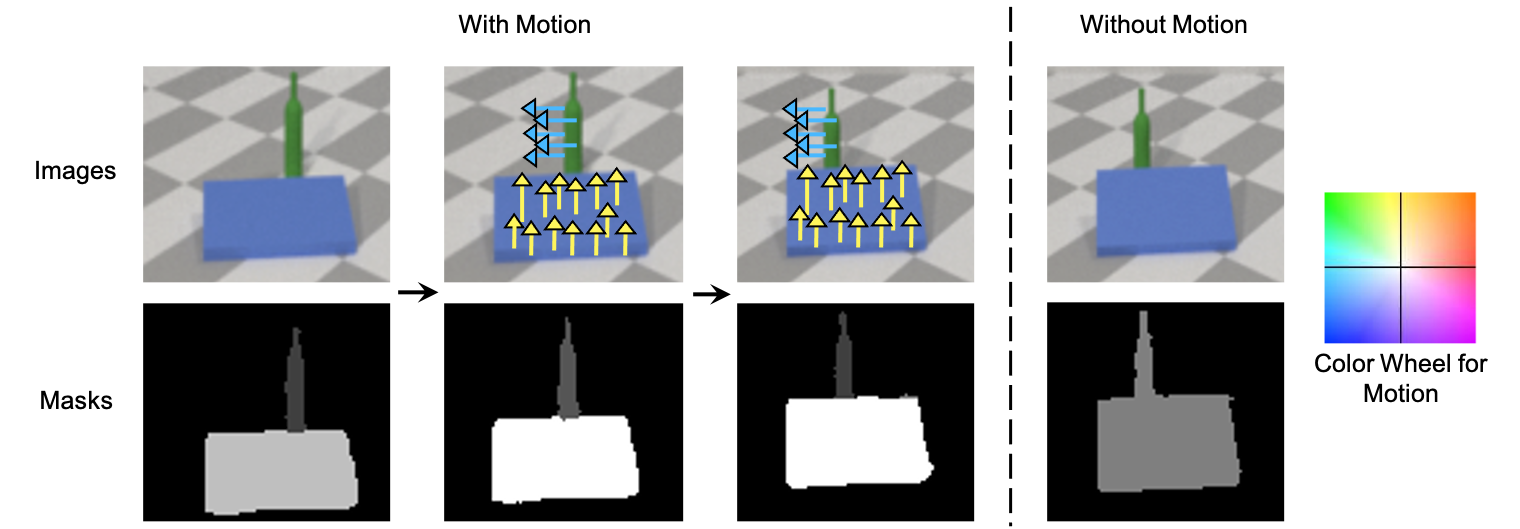
Figure 1: Motion is an important cue for object segmentation from early in development. We combine motion with an approximate understanding of physics to discover 3D objects that are physically consistent across time. In the video above, motion cues (shown with colored arrows) enable our model to modify our predictions from a single large incorrect segmentation mask to two smaller correct masks.
Abstract
We study the problem of unsupervised physical object discovery. While existing frameworks aim to decompose scenes into 2D segments based off each object's appearance, we explore how physics, especially object interactions, facilitates disentangling of 3D geometry and position of objects from video, in an unsupervised manner. Drawing inspiration from developmental psychology, our Physical Object Discovery Network (POD-Net) uses both multi-scale pixel cues and physical motion cues to accurately segment observable and partially occluded objects of varying sizes, and infer properties of those objects. Our model reliably segments objects on both synthetic and real scenes. The discovered object properties can also be used to reason about physical events.