Yilun Du
Email: yilundu [at] mit [dot] edu
Twitter: https://twitter.com/du_yilun
Github: https://github.com/yilundu
CV: CV
I am a final year PhD student at MIT EECS, advised by Prof. Leslie Kaelbling, Prof. Tomas Lozano-Perez and Prof. Joshua B. Tenenbaum. Previously, I obtained my bachelor's degree from MIT, was a research fellow at OpenAI, an intern and visiting researcher at FAIR and Google Deepmind, and got a gold medal at the International Biology Olympiad. My research focuses on generative models, decision making, robot learning, embodied agents, and the applications of such tools to scientific domains.
My research is driven by the goal of developing intelligent embodied agents that interact in the physical world. My research has primarily focused on the use of generative AI as an approach towards this goal. A major challenge in applying generative AI in this setting is the lack of available decision-making data and the necessity to generalize well to previously unseen situations. My work addresses this by constructing composable generative models using the idea of learning energy landscapes as a means to generalize beyond the narrow amount of data that is available. Such composable models enable compositional visual generation and compositional scene understanding. My work has further focused on how such compositional models can enable the synthesis of new trajectories in trajectory planning, enabling flexible adaptation to novel goals and rewards across both synthesized videos and on real robots. Finally, an energy optimization perspective on prediction enables us to combine the strengths of large pre-trained models together at prediction time, enabling both hierarchical planning and multimodal perception. More broadly, I am interested in constructing a decentralized generative architecture for decision-making, consisting of a society of different multimodal models, each with separate responsibilities such as 3D perception, memory, and auditory understanding, which jointly cooperate to make decisions in an environment. I am also interested in additional techniques to improve generative models such as reinforcement learning training as well as broader applications of my research in domains in science such as computational biology.
News
- I am looking for academic positions this upcoming year! You can find my research statement here.
- We are organizing a workshop on foundation models for decision making at NeurIPS 2023 and a workshop on generative models for decision making at ICLR 2024!
- I gave a recent talks summarizing my work on compositional generative models and on using video models in robotics.
- Check out a list of our work on energy-based models!
Research Highlights
- Generative Modeling: constructing generative models of the world.
- Perception and Scene Understanding: inferring the 3D / visual structure of the world.
- Interactive Learning: building agents which may interact in the world.
Publications ( show selected / show all by date / show all by topic )
Topics: Generative Modeling / Perception and Scene Understanding / Interactive Learning (* indicates equal contribution and † indicates equal advising)
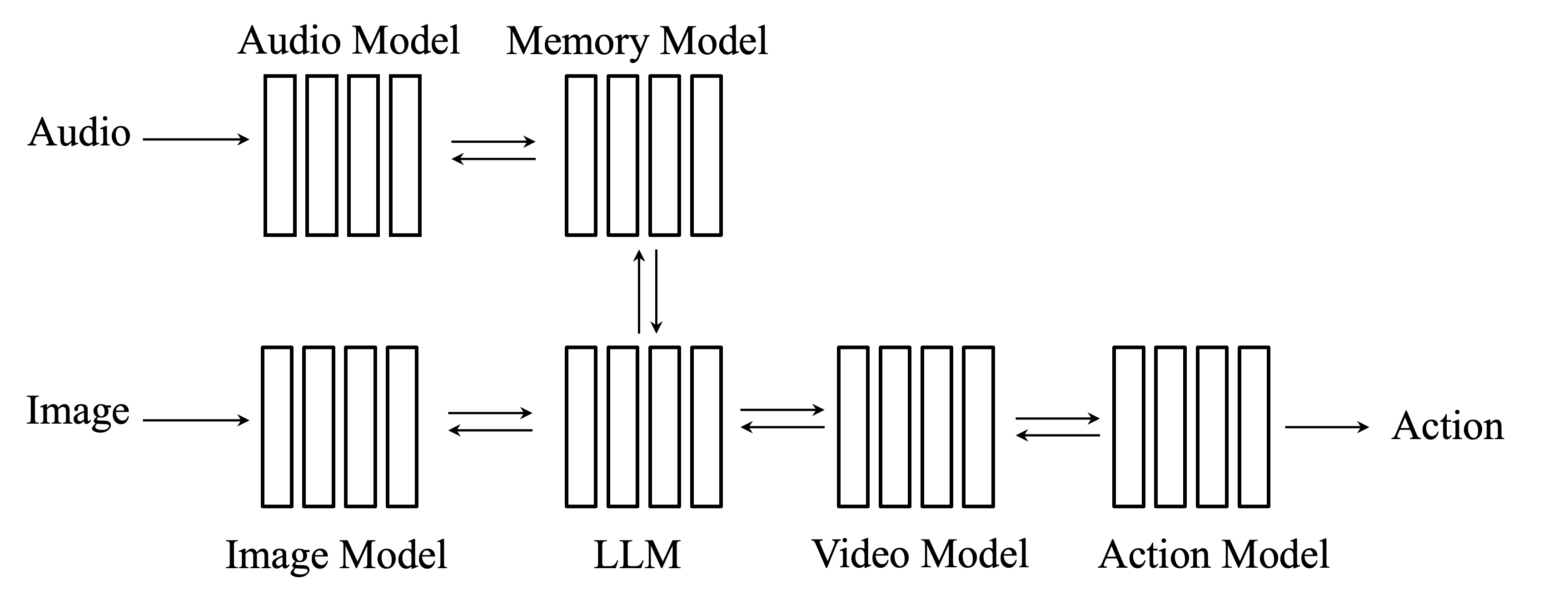
Compositional Generative Modeling: A Single Model is Not All You Need
Yilun Du, Leslie Kaelbling
ArXiv Preprint / Paper
Video Language Planning
Yilun Du, Sherry Yang, Pete Florence, Fei Xia, Ayzaan Wahid, Brian Ichter, Pierre Sermanet, Tianhe Yu, Pieter Abbeel, Joshua B. Tenenbaum, Leslie Kaelbling, Andy Zeng, Jonathan Tompson
Learning to Act from Actionless Video through Dense Correspondences
Po-Chen Ko, Jiayuan Mao, Yilun Du, Shao-Hua Sun, Joshua B. Tenenbaum

Learning Interactive Real-World Simulators
Mengjiao Yang, Yilun Du, Kamyar Ghasemipour, Jonathan Tompson, Leslie Kaelbling, Dale Schuurmans, Pieter Abbeel
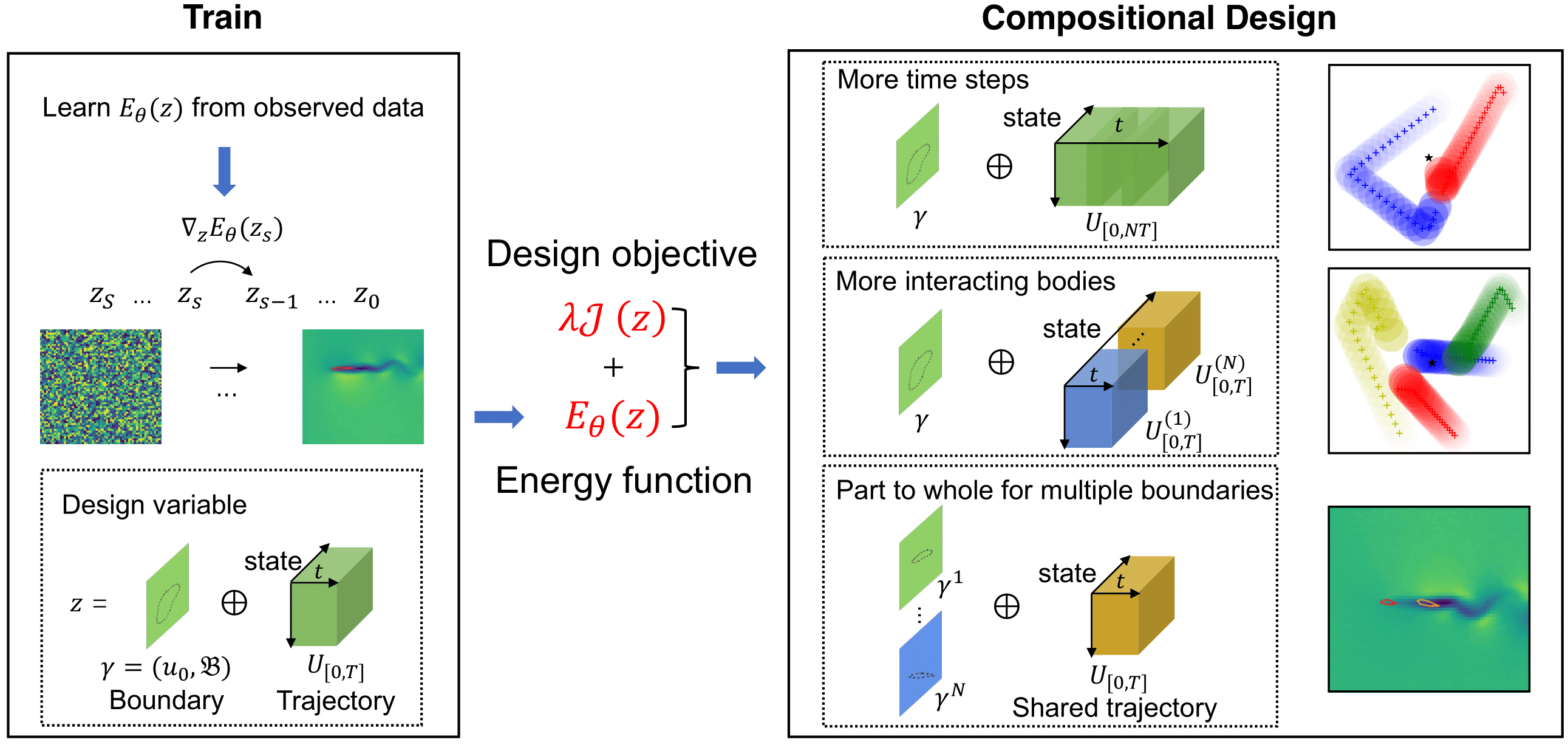
Compositional Generative Inverse Design
Tailin Wu*, Takashi Maruyama*, Long Wei*, Tao Zhang*, Yilun Du*, Gianluca Iaccarino, Jure Leskovec
Probabilistic Adaptation of Text-to-Video Models
Mengjiao Yang*, Yilun Du*, Bo Dai, Dale Schuurmans, Joshua B. Tenenbaum, Pieter Abbeel

Training Diffusion Models with Reinforcement Learning
Kevin Black*, Michael Janner*, Yilun Du, Ilya Kostrikov, Sergey Levine
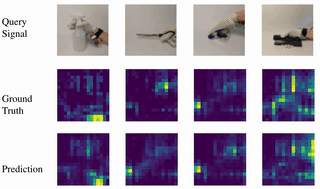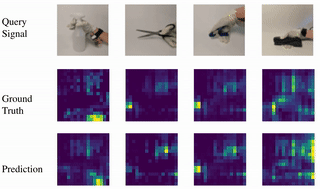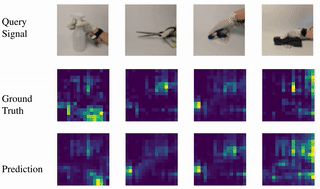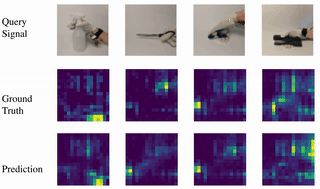
Learning to Jointly Understand Visual and Tactile Signals
Yichen Li, Yilun Du, Chao Liu, Chao Liu, Francis Williams, Michael Foshey, Benjamin Eckart, Jan Kautz, Joshua B. Tenenbaum, Antonio Torralba, Wojciech Matusik
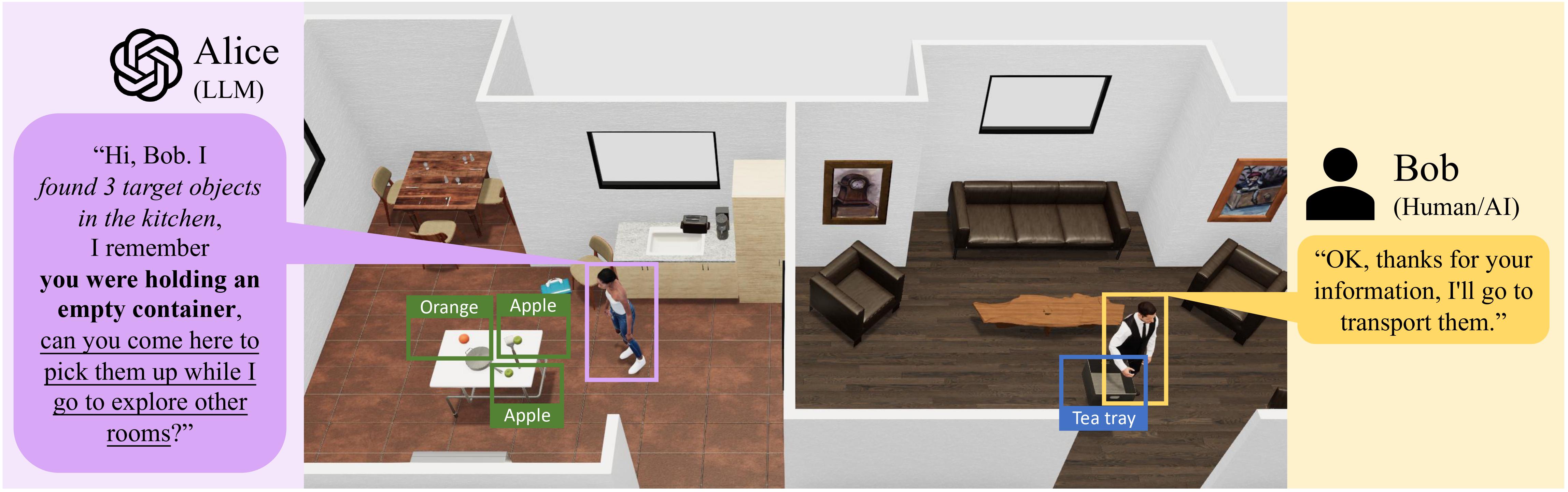
Building Cooperative Embodied Agents Modularly with Large Language Models
Hongxin Zhang, Weihua Du, Jiaming Shan, Qinhong Zhou, Yilun Du, Joshua B. Tenenbaum, Tianmin Shu, Chuang Gan

HAZARD Challenge: Embodied Decision Making in Dynamically Changing Environments
Qinhong Zhou, Sunli Chen, Yisong Wang, Haozhe Xu, Weihua Du, Hongxin Zhang, Yilun Du, Joshua B. Tenenbaum, Chuang Gan
Improving Factuality and Reasoning in Language Models through Multiagent Debate
Yilun Du, Shuang Li, Antonio Torralba, Joshua B. Tenenbaum, Igor Mordatch
Compositional Foundation Models for Hierarchical Planning
Anurag Ajay*, Seungwook Han*, Yilun Du*, Shuang Li, Abhi Gupta, Tommi Jaakkola, Joshua B. Tenenbaum, Leslie Kaelbling, Akash Srivastava, Pulkit Agrawal
NeurIPS 2023 / Website / Paper / Code
Learning Universal Policies via Text-Guided Video Generation
Yilun Du*, Mengjiao Yang*, Bo Dai, Hanjun Dai, Ofir Nachum, Joshua B. Tenenbaum, Dale Schuurmans, Pieter Abbeel
NeurIPS 2023 (Spotlight) / Website / Paper

DiffuseBot: Breeding Soft Robots With Physics-Augmented Generative Diffusion Models
Tsun-Hsuan Wang, Juntian Zheng, Pingchuan Ma, Yilun Du, Byungchul Kim, Andrew Spielberg, Joshua Tenenbaum, Chuang Gan, Daniela Rus
NeurIPS 2023 (Oral) / Website / Paper
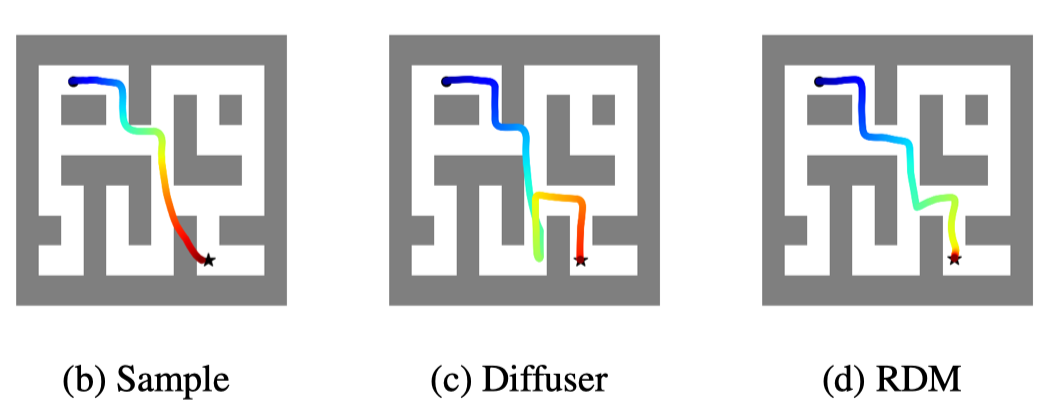
Adaptive Online Replanning with Diffusion Models
Siyuan Zhou, Yilun Du, Shun Zhang, Mengdi Xu, Yikang Shen, Wei Xiao, Dit-Yan Yeung, Chuang Gan
NeurIPS 2023 / Website / Code / Paper

3D-LLM: Injecting the 3D World into Large Language Models
Yining Hong, Haoyu Zhen, Peihao Chen, Shuhong Zheng, Yilun Du, Zhenfang Chen, Chuang Gan
NeurIPS 2023 (Spotlight) / Website / Paper / Code
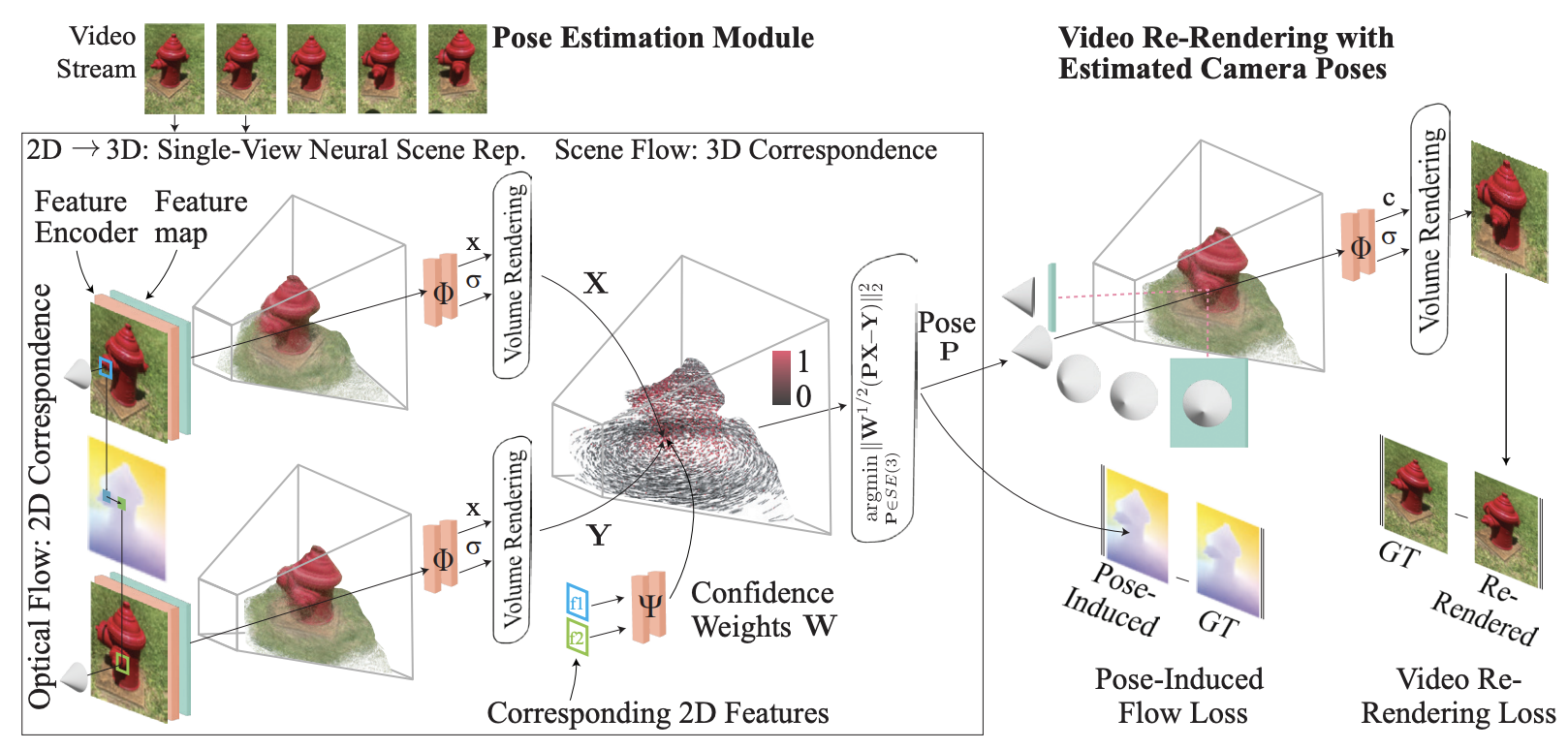
FlowCam: Training Generalizable 3D Radiance Fields without Camera Poses via Pixel-Aligned Scene Flow
Cameron Smith, Yilun Du, Ayush Tewari, Vincent Sitzmann
NeurIPS 2023 / Website / Paper / Code
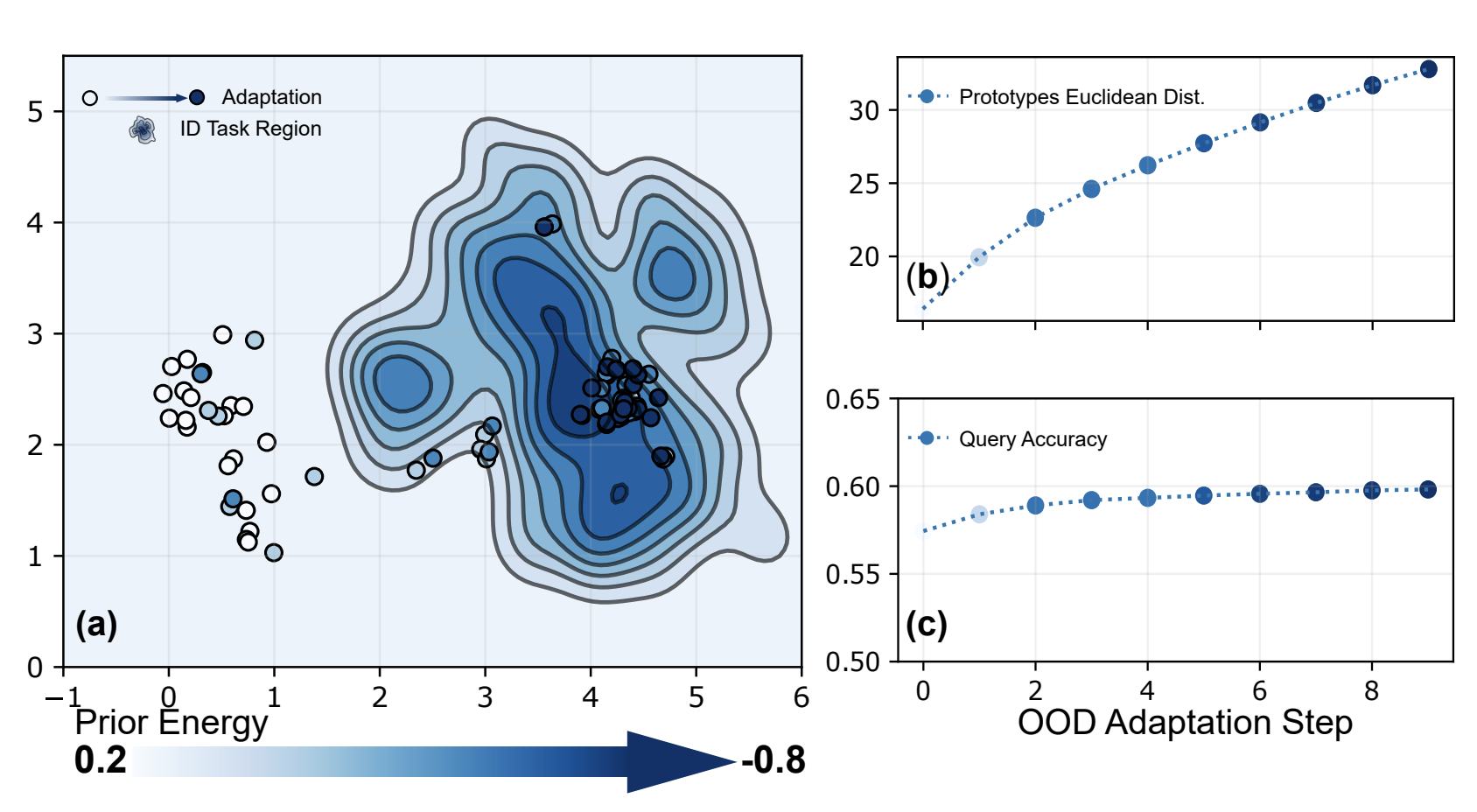
Secure Out-of-Distribution Task Generalization with Energy-Based Models
Shengzhuang Chen, Long-Kai Huang, Jonathan Schwarz, Yilun Du, Ying Wei

Compositional Diffusion-Based Continuous Constraint Solvers
Zhutian Yang, Jiayuan Mao, Yilun Du, Jiajun Wu, Joshua B. Tenenbaum, Tomas Lozano-Perez, Leslie Kaelbling
Unsupervised Compositional Concepts Discovery with Text-to-Image Generative Models
Nan Liu*, Yilun Du*, Shuang Li*, Joshua B. Tenenbaum, Antonio Torralba
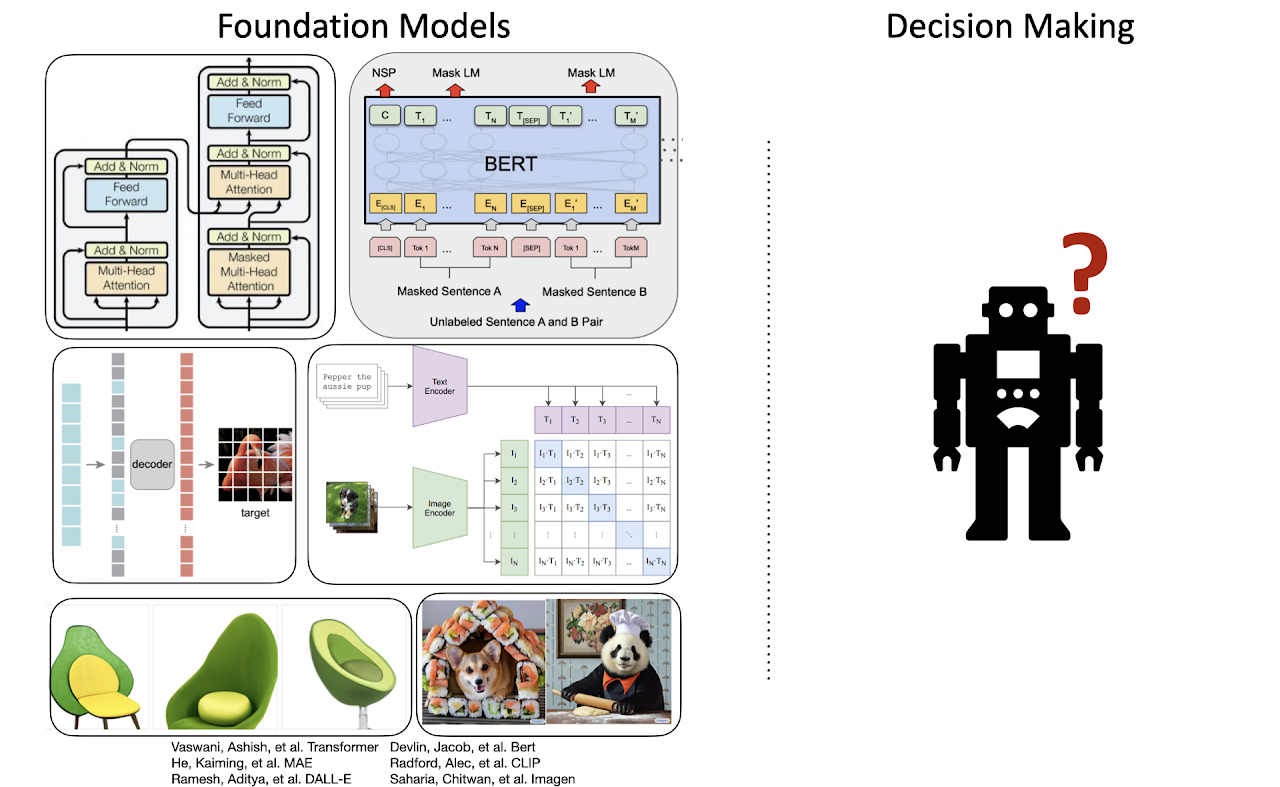
Foundation Models for Decision Making: Problems, Methods, and Opportunities
Mengjiao Yang, Ofir Nachum, Yilun Du, Jason Wei, Pieter Abbeel, Dale Schuurmans
ArXiv Preprint / Paper
Reduce, Reuse, Recycle: Compositional Generation with Energy-Based Diffusion Models and MCMC
Yilun Du, Conor Durkan, Robin Strudel, Joshua B. Tenenbaum, Sander Dieleman, Rob Fergus, Jascha Sohl-Dickstein, Arnaud Doucet, Will Grathwohl
ICML 2023 / Website / Colab / Tapestry Colab / Code / Paper
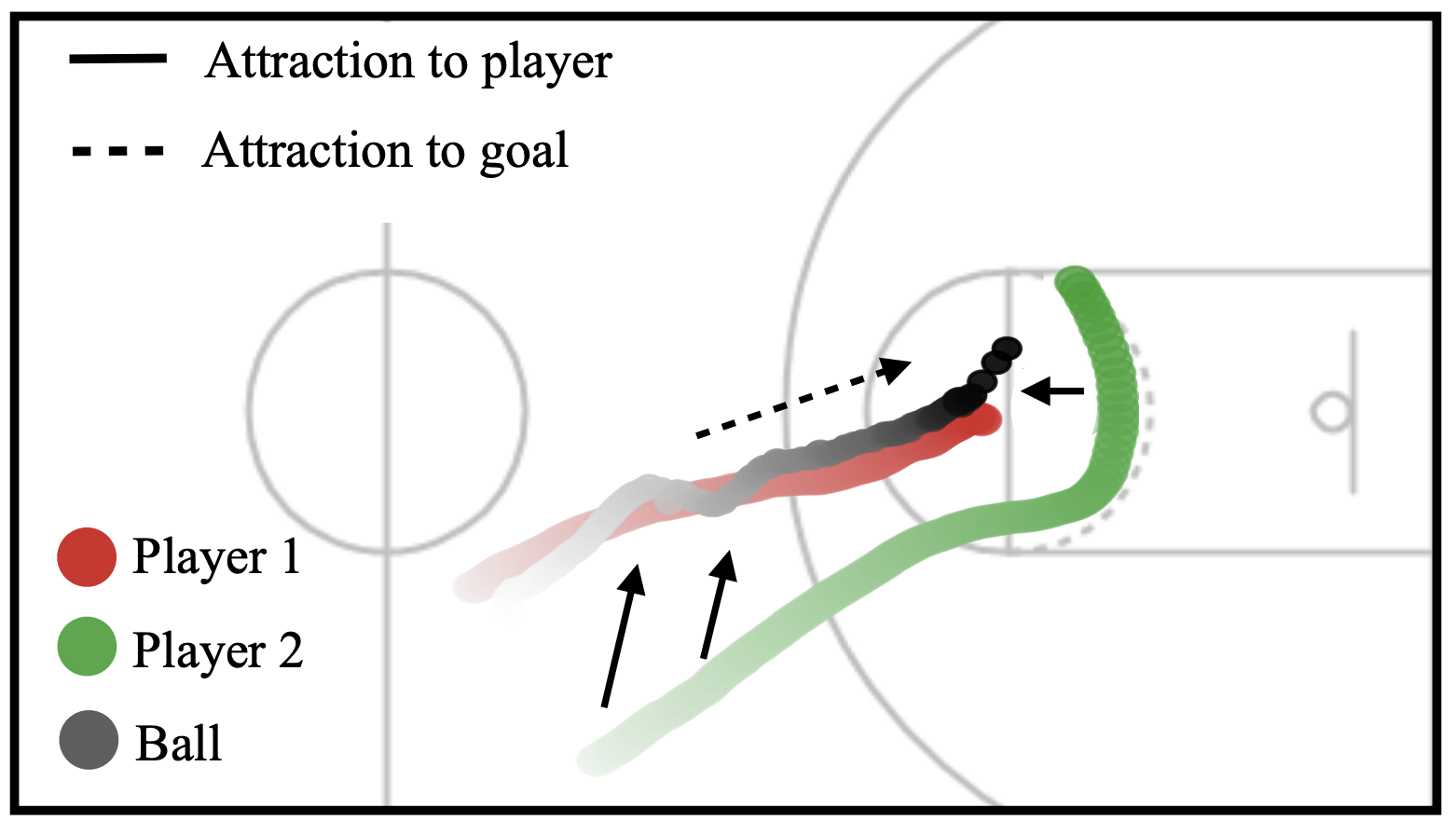
Inferring Relational Potentials in Interacting Systems
Armand Comas, Yilun Du, Christian Fernandez, Sandesh Ghimire, Mario Sznaier, Joshua B. Tenenbaum, Octavia Camps
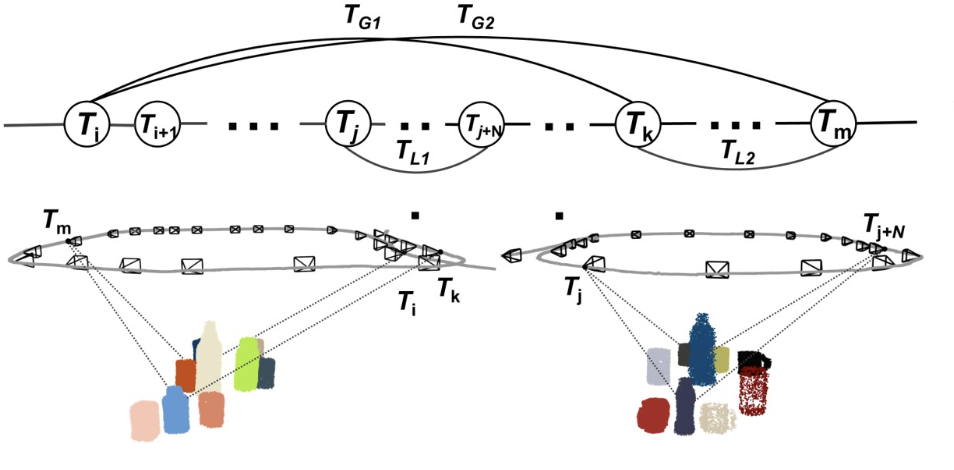
NeuSE: Neural SE(3)-Equivariant Embedding for Consistent Spatial Understanding with Objects
Jiahui Fu, Yilun Du, Kurran Singh, Joshua B. Tenenbaum, John J. Leonard
RSS 2023 / ICRA 2023 RAP4Robots Workshop (Outstanding Paper Award) / Website / Paper

StructDiffusion: Language-Guided Creation of Physically-Valid Structures using Unseen Objects
Weiyu Liu, Yilun Du, Tucker Hermans, Sonia Chernova, Chris Paxton

Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
Cheng Chi, Siyuan Feng, Yilun Du, Zhenjia Xu, Eric Cousineau, Benjamin Burchfiel, Shuran Song
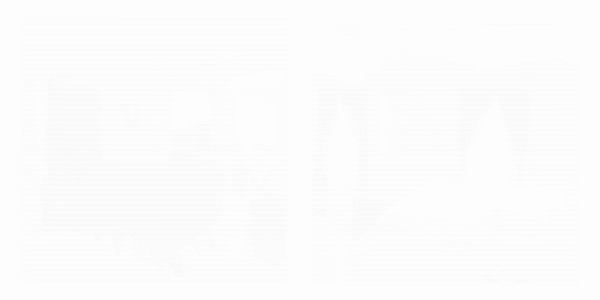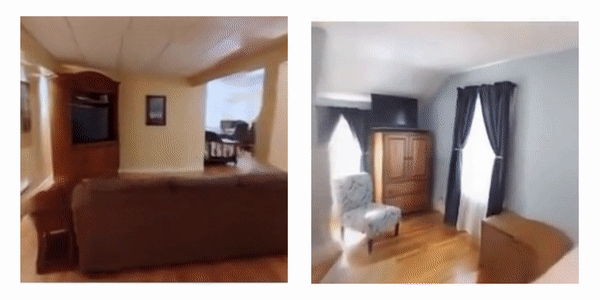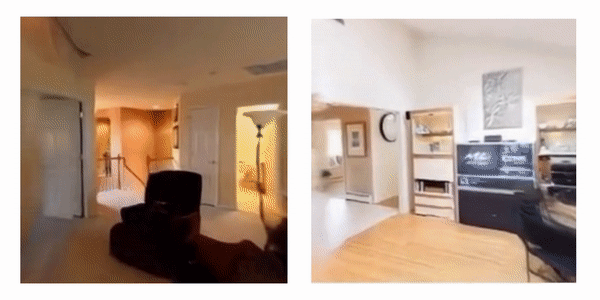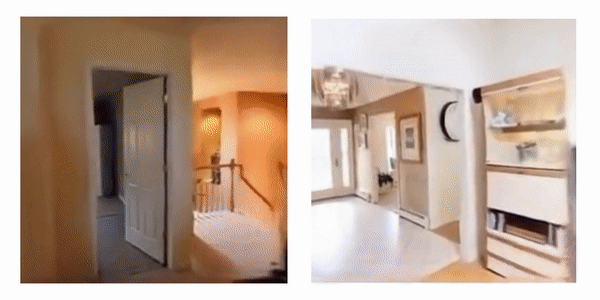
Learning to Render Novel Views from Wide-Baseline Stereo Pairs
Yilun Du, Cameron Smith, Ayush Tewari†, Vincent Sitzmann†

3D Concept Learning and Reasoning from Multi-View Images
Yining Hong, Chunru Lin, Yilun Du, Zhenfang Chen, Joshua B. Tenenbaum, Chuang Gan
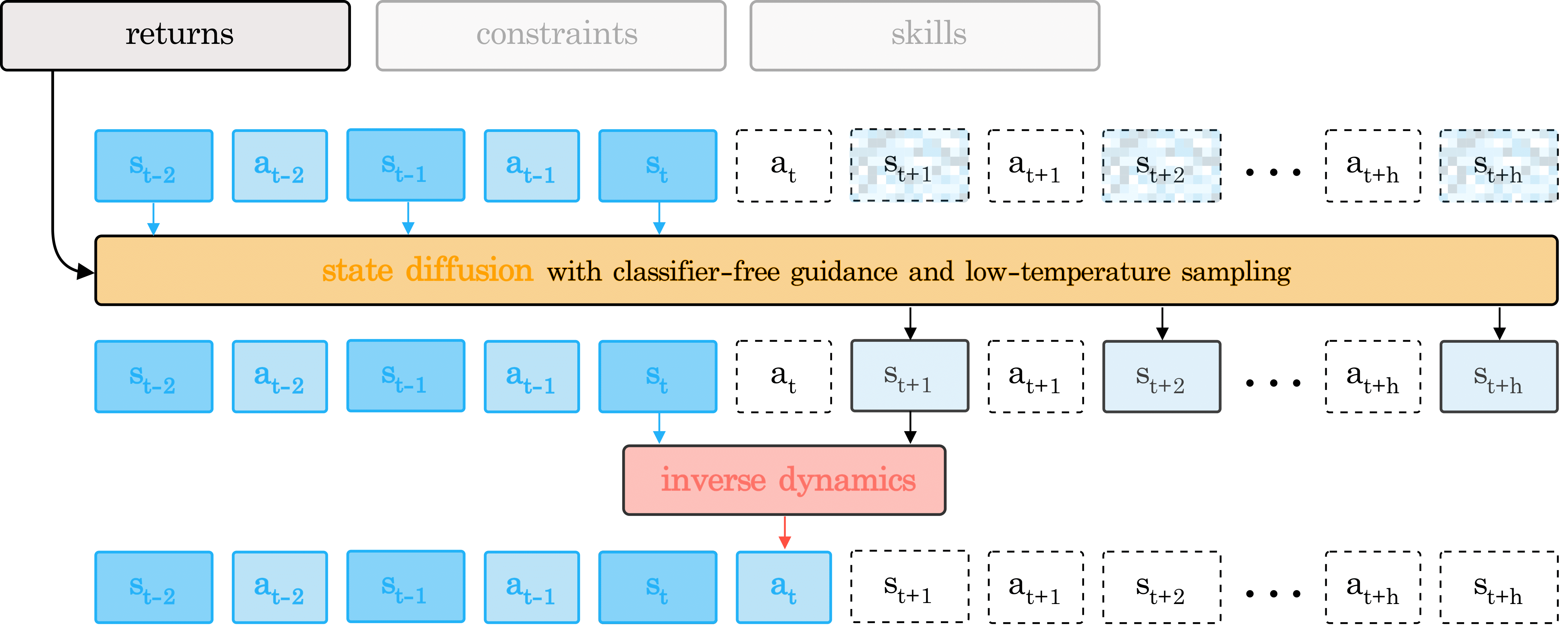
Is Conditional Generative Modeling all You Need for Decision-Making?
Anurag Ajay*, Yilun Du*, Ahbi Gupta*, Joshua B. Tenenbaum, Tommi S. Jaakkola, Pulkit Agrawal
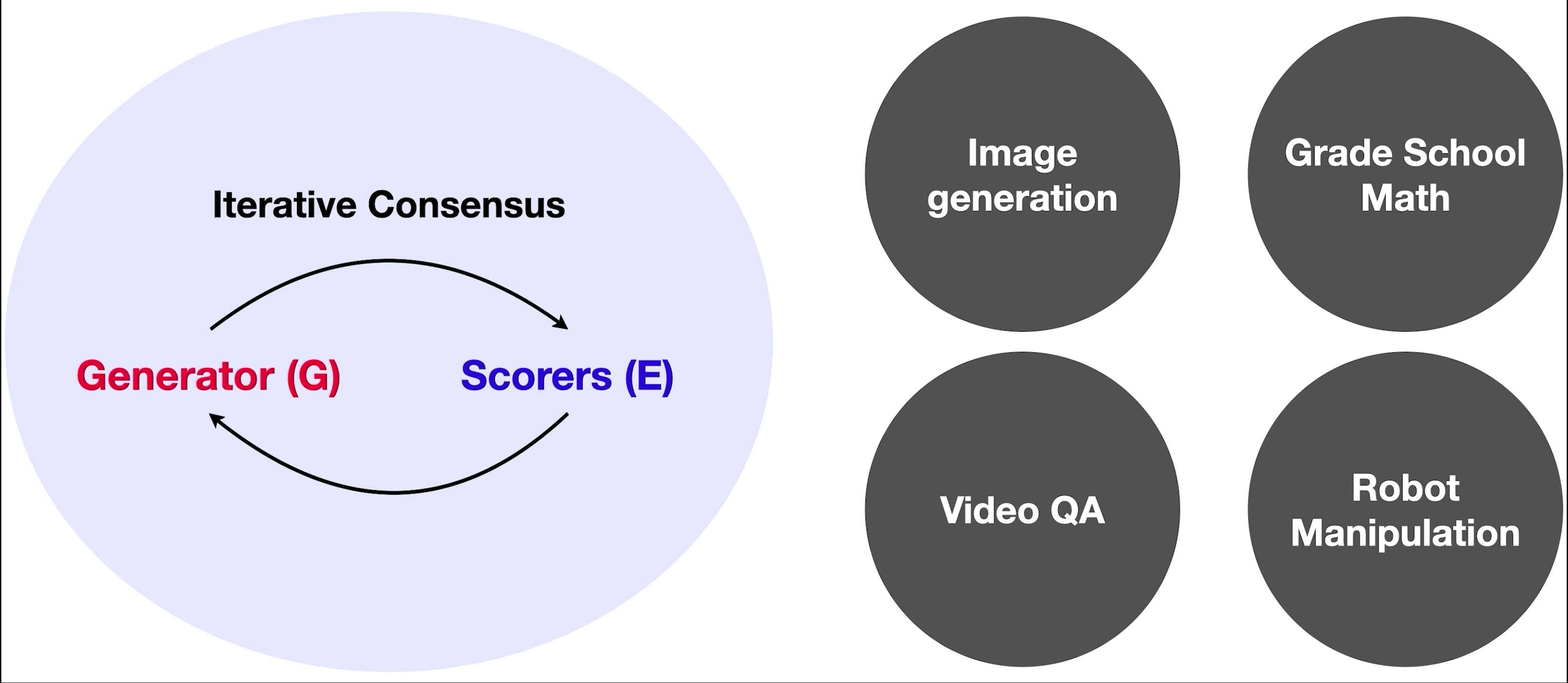
Composing Ensembles of Pre-trained Models via Iterative Consensus
Shuang Li*, Yilun Du*, Joshua B. Tenenbaum, Antonio Torralba, Igor Mordatch
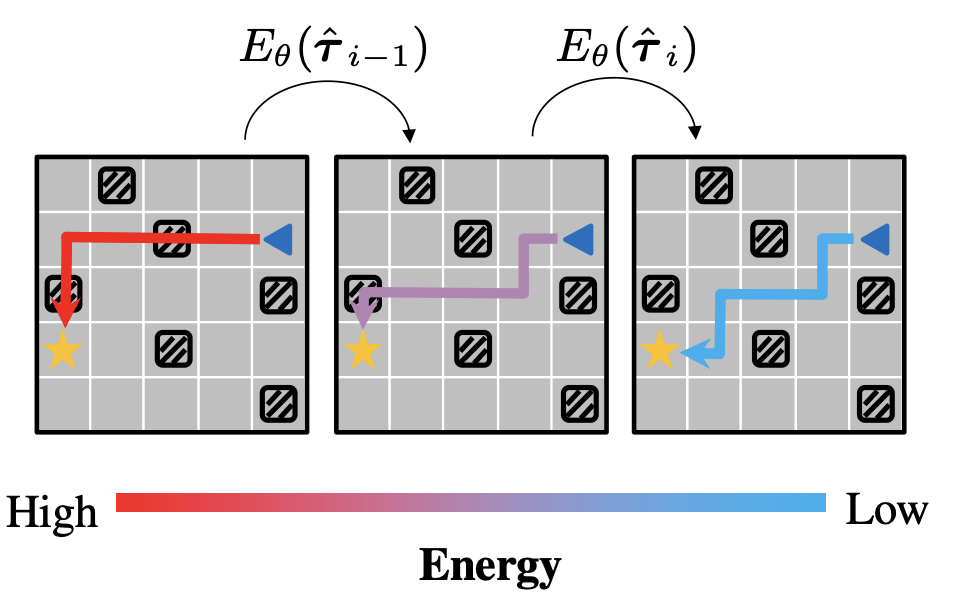
Planning with Sequence Models through Iterative Energy Minimization
Hongyi Chen*, Yilun Du*, Yiye Chen*, Joshua B. Tenenbaum, Patricio Antonio Vela

Seeing 3D Objects in a Single Image via Self-Supervised Static-Dynamic Disentanglement
Prafull Sharma, Ayush Tewari, Yilun Du, Sergey Zakharov, Rares Ambrus, Adrien Gaidon, William T. Freeman, Fredo Durand, Joshua B. Tenenbaum, Vincent Sitzmann

Local Neural Descriptor Fields: Locally Conditioned Object Representations for Manipulation
Ethan Chun, Yilun Du, Anthony Simeonov, Tomas Lozano-Perez, Leslie Kaelbling

Visiblity-Aware Navigation Among Movable Objects
Jose Iturralde*, Aiden Curtis*, Yilun Du, Leslie Kaelbling, Tomas Lozano-Perez
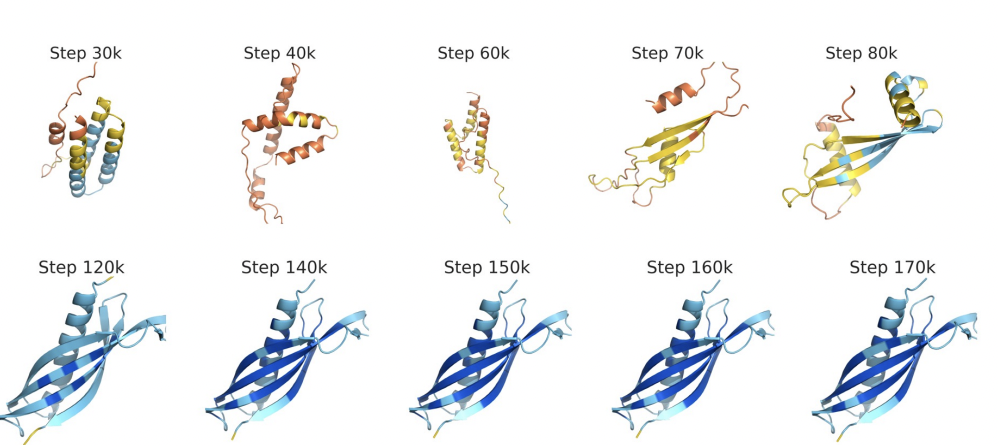
Language Models Generalize Beyond Natural Proteins
Robert Verkuil*, Ori Kabeli*, Yilun Du, Basile Wicky, Lukas Milles, Justas Dauparas, David Baker, Sergey Ovchinnikov, Tom Sercu, Alexander Rives
bioRxiv Preprint / Paper
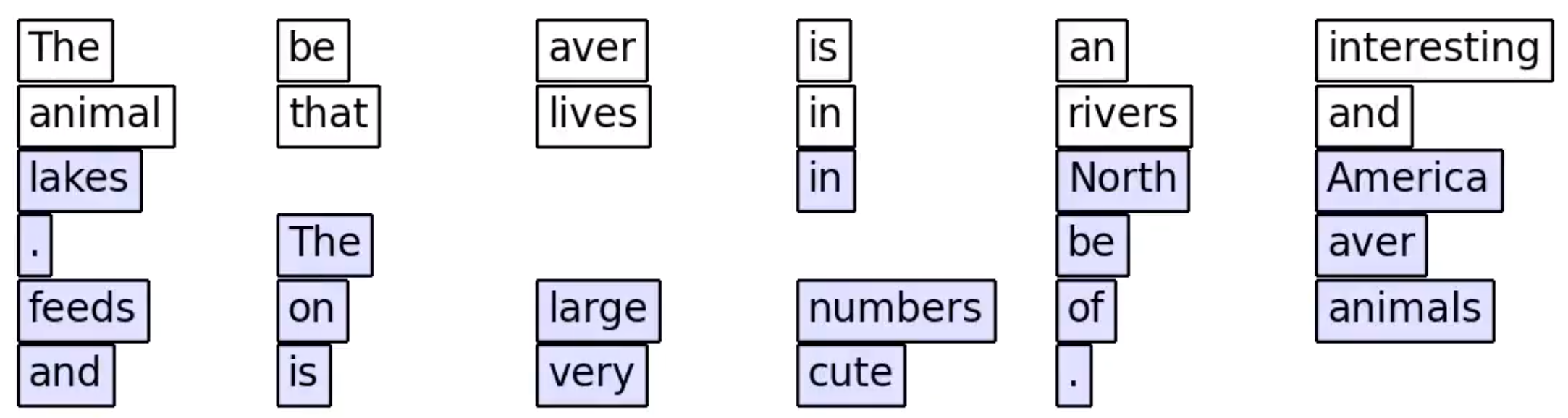
Self-conditioned Embedding Diffusion for Text Generation
Robin Strudel, Corentin Tallec, Florent Altche, Yilun Du, Yaroslav Ganin, Arthur Mensch, Will Grathwohl, Nikolay Savinov, Sander Dieleman, Laurent Sifre, Remi Lebond
ArXiv Preprint / Paper

SE(3)-Equivariant Relational Rearrangement with Neural Descriptor Fields
Anthony Simeonov*, Yilun Du*, Yen-Chen Lin, Alberto Rodriguez, Leslie Kaelbling, Tomas Lozano-Perez, Pulkit Agrawal

MIRA: Mental Imagery for Robotic Affordances
Yen-Chen Lin, Pete Florence, Andy Zheng, Johnathon T. Barron, Yilun Du, Wei-Chiu Ma, Anthony Simeonov, Alberto Rodriguez, Phillip Isola
Learning Neural Acoustic Fields
Andrew Luo, Yilun Du, Michael J. Tarr, Joshua B. Tenenbaum, Antonio Torralba, Chuang Gan
NeurIPS 2022 / Website / Paper / Code / Colab

3D Concept Grounding on Neural Fields
Yining Hong, Yilun Du, Chunru Lin, Joshua B. Tenenbaum, Chuang Gan
NeurIPS 2022 / Website / Paper

Pre-Trained Language Models for Interactive Decision-Making
Shuang Li, Xavier Puig, Chris Paxton, Yilun Du, Clinton Wang, Linxi Fan, Tao Chen, De-An Huang, Ekin Akyurek, Anima Anandkumar+, Jacob Andreas+, Igor Mordatch+, Antonio Torralba+, Yuke Zhu+
NeurIPS 2022 (Oral) / Website / Paper / Code
(Last five authors contributed equally; order determined by alphabetically.)Compositional Visual Generation with Composable Diffusion Models
Nan Liu*, Shuang Li*, Yilun Du*, Antonio Torralba, Joshua B. Tenenbaum
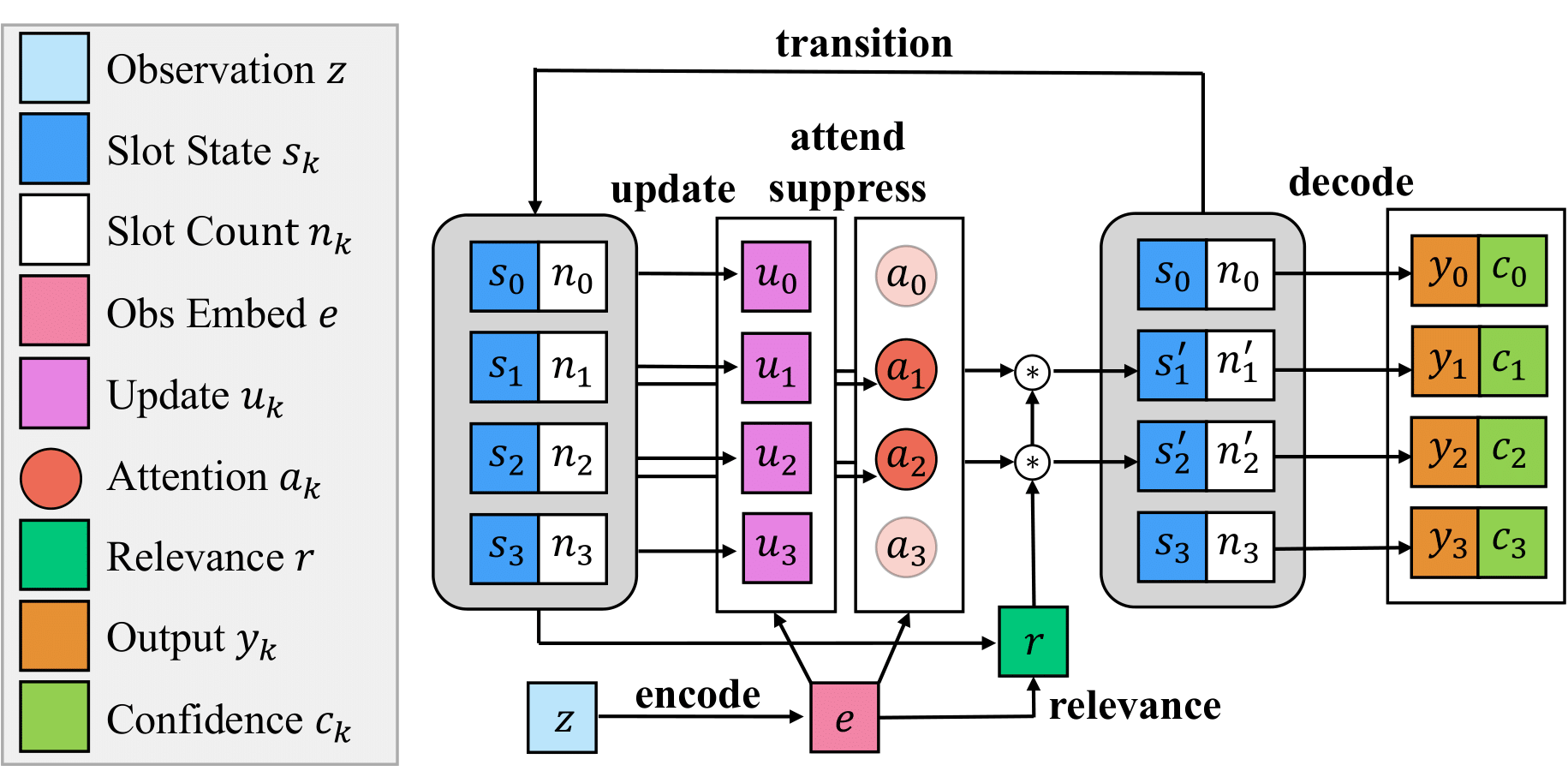
Learning Object Based State Estimators for Household Autonomy
Yilun Du, Tomas Lozano-Perez, Leslie Kaelbling

Robust Change Detection Based on Neural Descriptor Fields
Jiahui Fu, Yilun Du, Kurran Singh, Joshua B. Tenenbaum, John J. Leonard
Planning with Diffusion for Flexible Behavior Synthesis
Michael Janner*, Yilun Du*, Joshua B. Tenenbaum, Sergey Levine
Learning Iterative Reasoning through Energy Minimization
Yilun Du, Shuang Li, Joshua B. Tenenbaum, Igor Mordatch
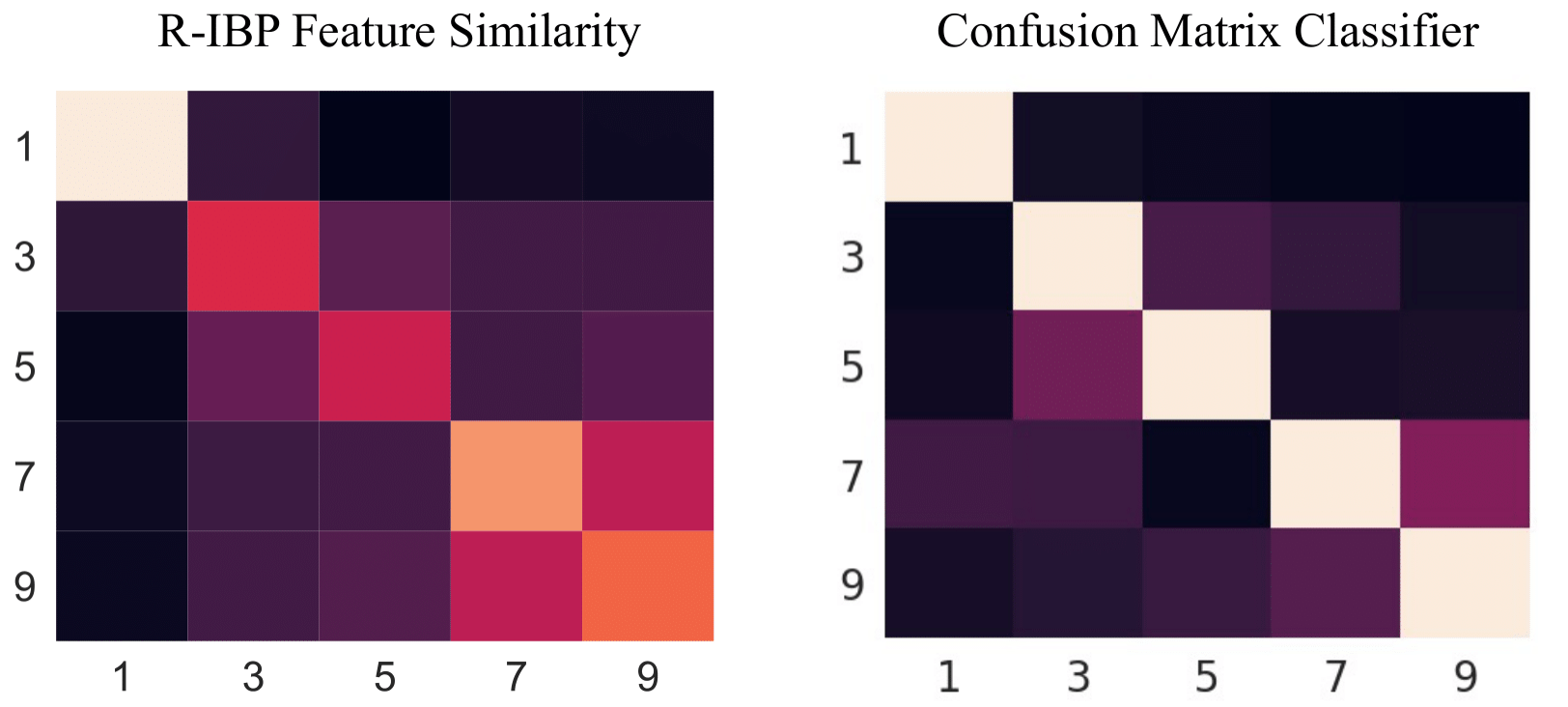
Streaming Inference for Infinite Feature Models
Rylan Schaeffer, Yilun Du, Gabrielle Liu, Ila Fiete
Energy-Based Models for Continual Learning
Shuang Li, Yilun Du, Gido M. van de Ven, Antonio Torralba, Igor Mordatch
CoLLA 2022 (Oral) / Paper / Project Page / Code
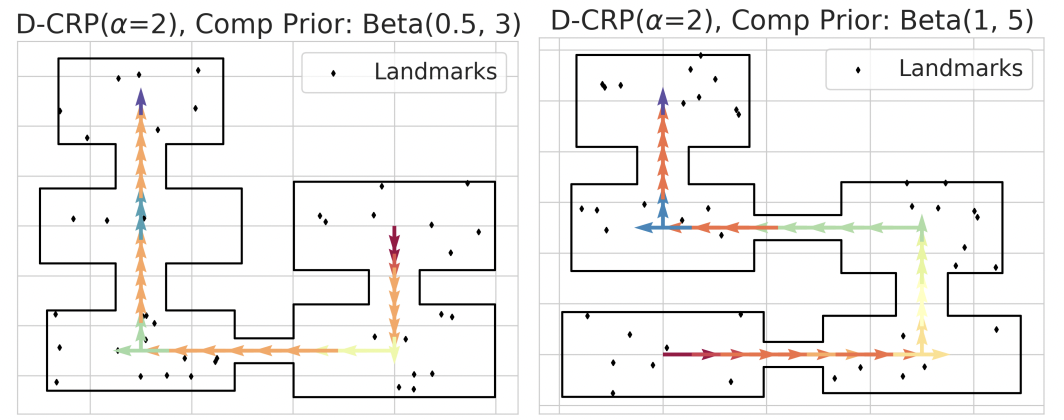
Streaming Inference for Infinite Non-Stationary Clustering
Rylan Schaeffer, Gabrielle Liu, Yilun Du, Scott Linderman, Ila Fiete

Kubric: A Scalable Dataset Generator
Klaus Greff, Francois Belleetti, Lucas Beyer, Carl Doersch, Yilun Du, Daniel Duckworth, David J. Fleet, Dan Gnanapragasam, Florian Golemo, Charles Herrmann, Thomas Kipf, Abhijit Kundu, Dmitry Lagun, issam Laradji, Derek Liu, Hinning Meyer, Yishu Miao, Derek Nowrouzezahrai, Cengiz Oztireli, Etienne Pot, Noha Radwan, Daniel Rebain, Sara Sabour, Mehdi Sajjadi, Matan Sela, Vincent Sitzmann, Austin Stone, Deqing Sun, Suhani Vora, Ziyu Wang, Tianhao Wu, Kwang Moo Yi, Fangcheng Zhong, Andrea Tagliasacchi

Neural Descriptor Fields: SE(3)-Equivariant Object Representations for Manipulation
Anthony Simeonov*, Yilun Du*, Andrea Tagliasacchi, Joshua B. Tenenbaum, Alberto Rodriguez, Pulkit Agrawal+, Vincent Sitzmann+
ICRA 2022 / Website / Paper / Code / Colab
(First two authors contributed equally; order determined by coin toss. Last two authors equal advising.)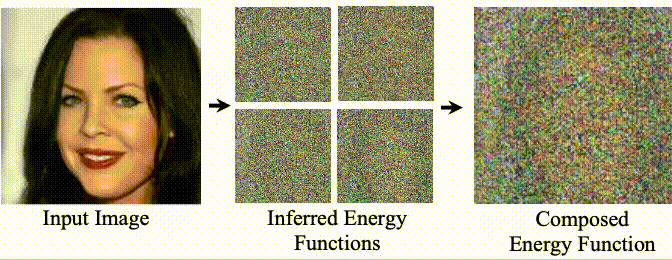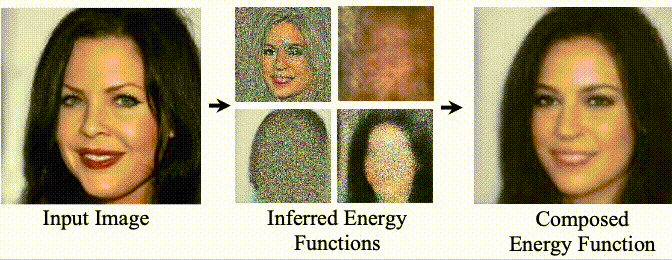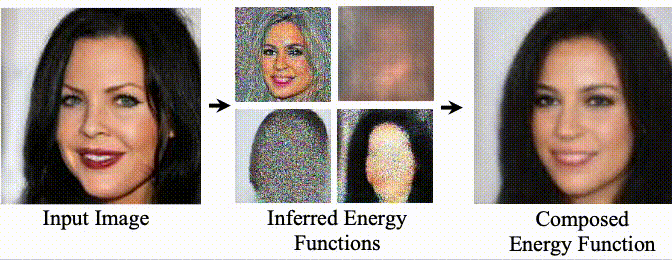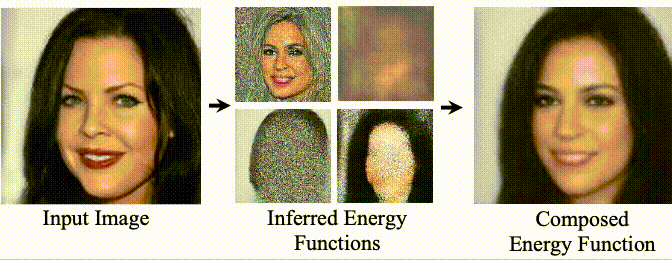
Unsupervised Learning of Compositional Energy Concepts
Yilun Du, Shuang Li, Yash Sharma, Joshua B. Tenenbaum, Igor Mordatch
NeurIPS 2021 / Website / Paper / Code
Learning to Compose Visual Relations
Nan Liu*, Shuang Li*, Yilun Du*, Joshua B. Tenenbaum, Antonio Torralba
NeurIPS 2021 (Spotlight) / NeurIPS 2021 Workshop on Controllable Generative Modeling (Outstanding Paper Award) / Website / Paper / Code / MIT News
Learning Signal-Agnostic Manifolds of Neural Fields
Yilun Du, Katie Collins, Joshua B. Tenenbaum, Vincent Sitzmann
NeurIPS 2021 / Website / Paper / Code

The Neural MMO Platform for Massively Multiagent Research
Joseph Suarez, Yilun Du, Clare Zhu, Igor Mordatch, Phillip Isola
NeurIPS 2021 Track on Datasets and Benchmarks / Website / Paper
3D Shape Generation and Completion through Point-Voxel Diffusion
Linqi Zhou, Yilun Du, Jiajun Wu
ICCV 2021 (Oral) / Project Page / Paper / Code
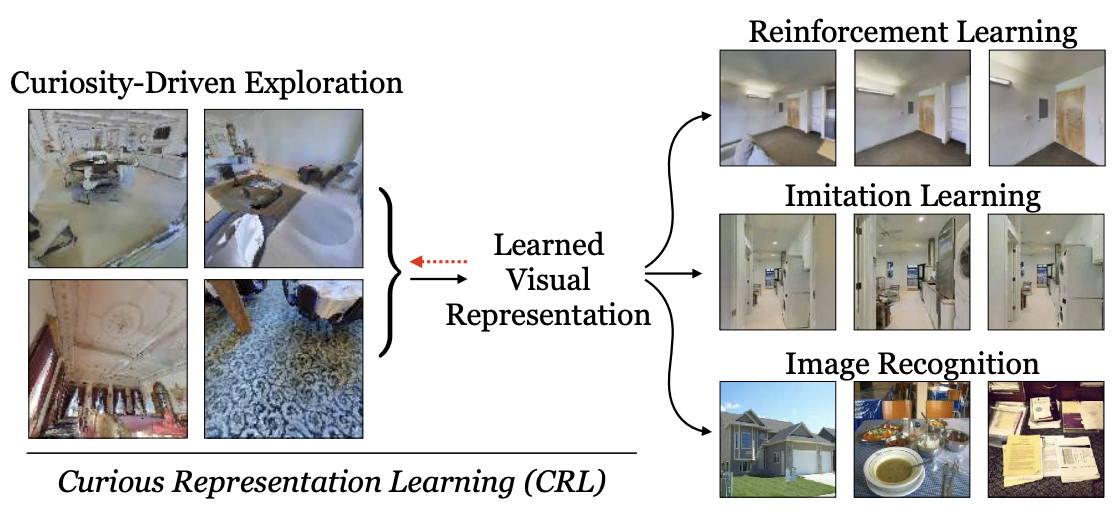
Curious Representation Learning for Embodied Intelligence
Yilun Du, Chuang Gan, Phillip Isola
ICCV 2021 / Project Page / Paper / Code

Neural Radiance Flow for 4D View Synthesis and Video Processing
Yilun Du, Yinan Zhang, Hong-Xing Yu, Joshua B. Tenenbaum, Jiajun Wu
ICCV 2021 / Paper / Project Page / Code

Weakly Supervised Human-Object Interaction Detection in Video via Contrastive Spatiotemporal Regions
Shuang Li, Yilun Du, Antonio Torralba, Josef Sivic, Bryan Russell
ICCV 2021 / Paper / Project Page / Code / Dataset
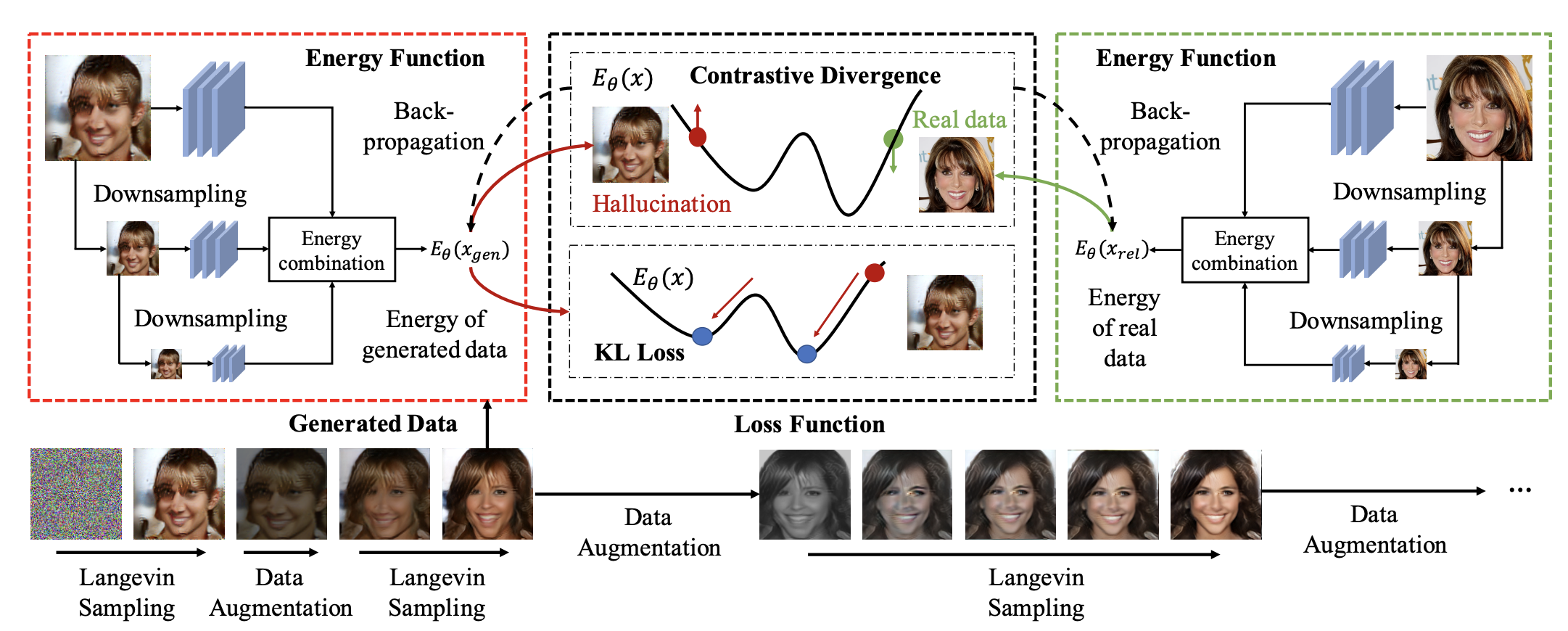
Improved Contrastive Divergence Training of Energy Based Models
Yilun Du, Shuang Li, Joshua B. Tenenbaum, Igor Mordatch
ICML 2021 / ICLR 2021 EBM Workshop (Oral) / Paper / Project Page / Code
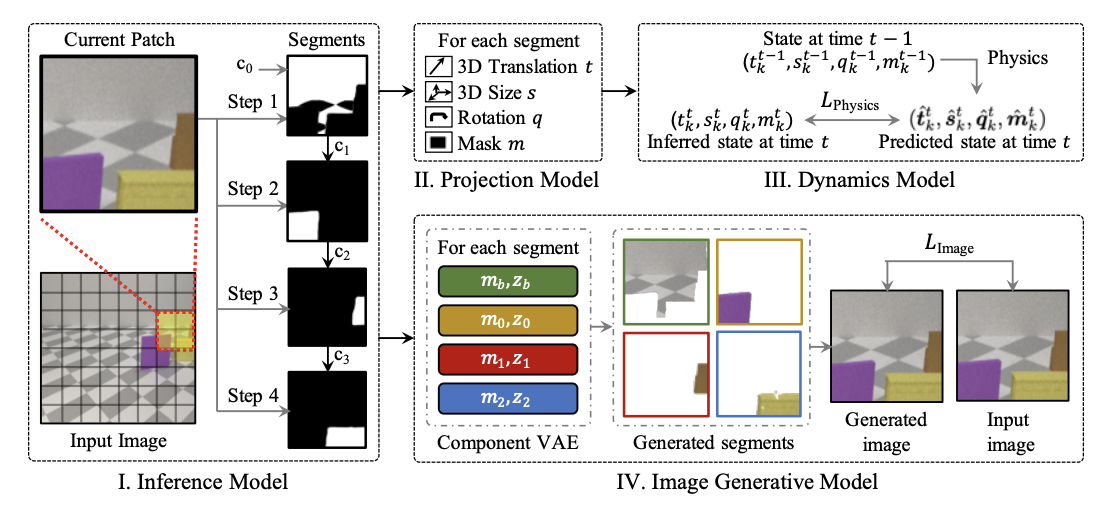
Unsupervised Discovery of 3D Physical Objects from Video
Yilun Du, Kevin Smith, Tomer Ulman, Joshua B. Tenenbaum, Jiajun Wu
ICLR 2021 / Paper / Code / Project Page

Compositional Visual Generation with Energy Based Models
Yilun Du, Shuang Li, Igor Mordatch
NeurIPS 2020 (Spotlight) / Paper / Project Page / Code
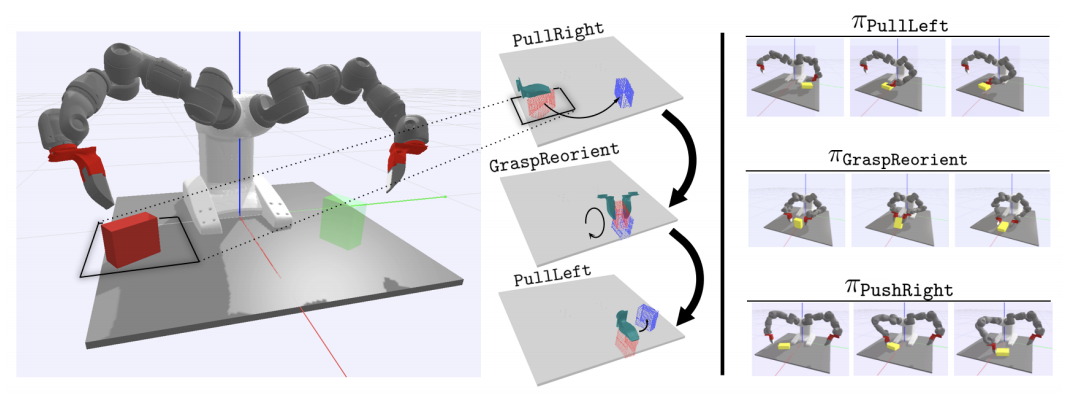
A Long Horizon Planning Framework for Manipulating Rigid Pointcloud Objects
Anthony Simeonov, Yilun Du, Beomjoon Kim, Francois Hogan, Joshua B. Tenenbaum, Pulkit Agrawal, Alberto Rodriguez
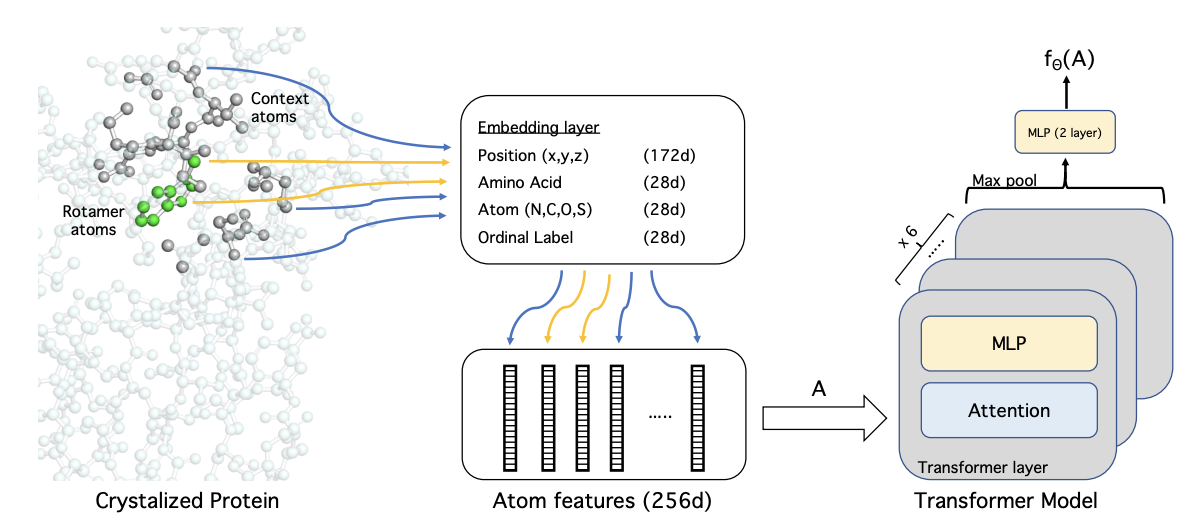
Energy-based models for atomic-resolution protein conformations
Yilun Du, Joshua Meier, Jerry Ma, Rob Fergus, Alexander Rives
ICLR 2020 (Spotlight) / MLCB 2020 (Oral / Travel Award) / Paper / Code
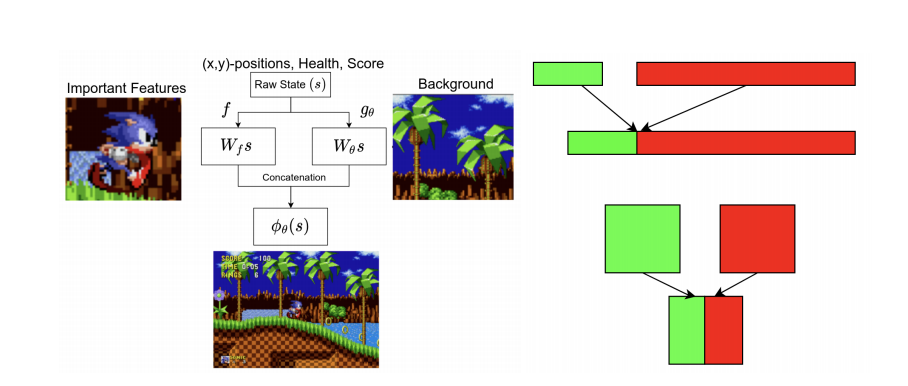
Observational Overfitting in Reinforcement Learning
Xingyou Song, Yiding Jiang, Yilun Du, Behnam Neyshabur
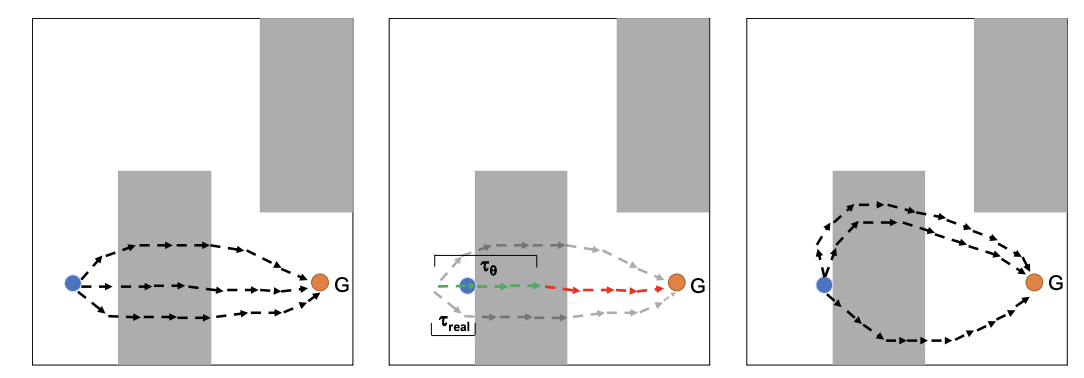
Model Based Planning with Energy Based Models
Yilun Du, Toru Lin, Igor Mordatch
CORL 2019 / ICML MBRL Workshop 2019 (Oral) / Paper / Code
Implicit Generation and Generalization with Energy Based Models
Yilun Du, Igor Mordatch
NeurIPS 2019 (Spotlight) / Paper / Website / Code / OpenAI Blog

Task-Agnostic Dynamics Priors for Deep Reinforcement Learning
Yilun Du, Karthik Narasimhan

Neural MMO: A massively multiplayer game environment for intelligent agents
Joseph Suarez, Yilun Du, Phillip Isola, Igor Mordatch